
Contents
Get a Personalized Demo
See how Torq harnesses AI in your SOC to investigate, prioritize, and respond to threats faster.
Key Takeaways
- The manual grind is over: True autonomous security shouldn’t require you to manually tag alerts or write rigid correlation rules just to teach a system how your SOC operates.
- Generic RAG fails in the SOC: Standard AI semantic searches hallucinate and match irrelevant data. High-stakes SecOps requires deterministic precision.
- Automated institutional memory: Torq Recall transforms an analyst’s everyday workflow — resolving cases and writing notes — into actionable, automated triage precedent.
- Honest AI builds trust: In messy, real-world environments, Torq Recall handles conflicting historical data by explicitly flagging discrepancies rather than blindly guessing.
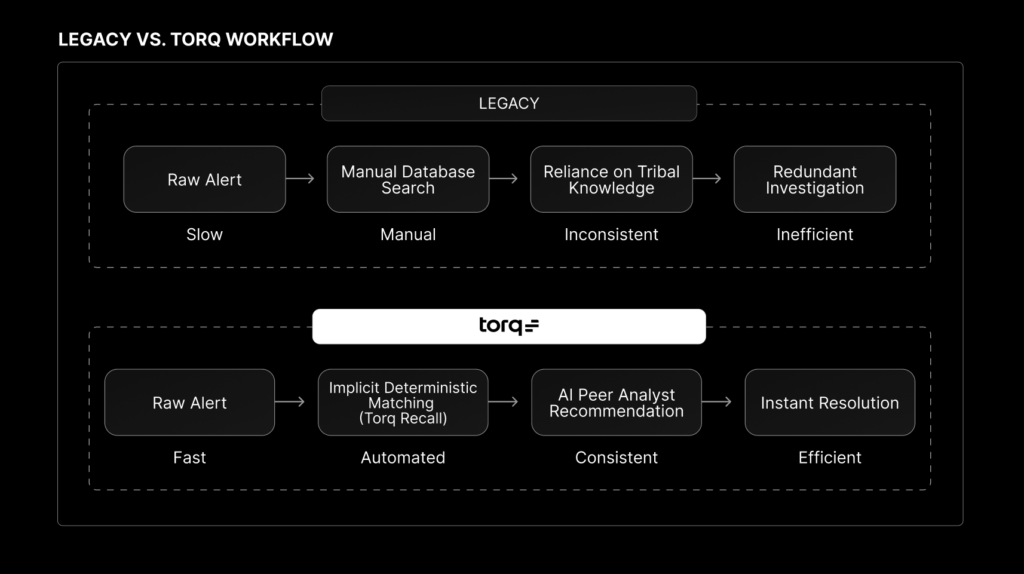
AI SOC memory is the difference between an investigation that starts from your team’s history and one that starts from zero. In most security operations centers, there is none: context disappears the moment a case closes. When a new alert fires, the investigation effectively starts from zero. Analysts are forced to rely on search interfaces — however advanced — to find similar past cases and determine whether an IP, file hash, or domain has been seen before and what the team concluded during the last investigation. But in an agentic SOC, even great search is still manual work; relevant precedent should be retrieved automatically at triage time.
Legacy case management systems weren’t built to retain this operational memory; they were built for tickets. To compensate, these systems require analysts to spend significant time manually gathering and connecting evidence to turn a raw alert into an actionable case. In other words, they demand that the analyst work for the system.
Without an automated way to recall past relevant resolutions, analysts repeatedly reinvestigate the exact same benign patterns the organization has already dismissed, creating the SOC equivalent of déjà vu and wasting valuable time. This inflates false-positive noise, drives alert fatigue, and keeps institutional knowledge siloed — meaning that when a senior analyst leaves, their tribal knowledge walks out the door with them.
True autonomous security requires a completely different architecture. A modern AI-native SOC shouldn’t force teams to change their habits or do extra data entry. Instead, it relies on implicit learning. By turning normal daily workflows — resolving a case and leaving a note — into continuous institutional memory, Torq Recall uses deterministic retrieval to automatically triage future threats based on an organization’s actual history.
The Cost of the Blank Slate
When an analyst investigates an alert without historical context, the problem is not just trivial duplication. The harder problem is recognizing patterns that are tightly connected to the specific user, asset, IP, domain, or behavior involved in the alert. For example, a login anomaly from a suspicious IP may appear risky in isolation, but historical cases may show that the same user and asset repeatedly trigger this pattern after legitimate travel or VPN use, and that the SOC has already validated it as benign.
External threat intelligence — like reputation scores and known IOC databases — is critical for establishing a baseline. But the ultimate context for triaging a new alert is internal: How did your specific organization resolve this exact pattern in the past? Was it tied to a legitimate corporate CDN? Was it an expected admin script?
Without an automated memory of past resolutions, false-positive noise inflates, and analysts burn out from repetitive manual triage.
Why Generic RAG Can’t Survive the SOC
As the industry integrates AI into security operations, Retrieval-Augmented Generation (RAG) has emerged as a popular approach for surfacing historical data. But standard semantic RAG struggles to meet the precision requirements of a modern SOC.
Generic RAG is designed to find semantically similar information. That works well for documents, summaries, and natural language knowledge. It breaks down when the “meaning” resides within security entities such as IP addresses, file hashes, URLs, hostnames, users, assets, or email addresses.
In security, two values can look almost identical and still represent completely different evidence. For example, two hash-like values such as 5jshdh2kfw and 5jshdh2yfw may look semantically close to a model, but in SecOps they are different identifiers and may point to completely different files. A near match is not evidence. In a high-stakes environment, “close enough” can shatter analyst trust.
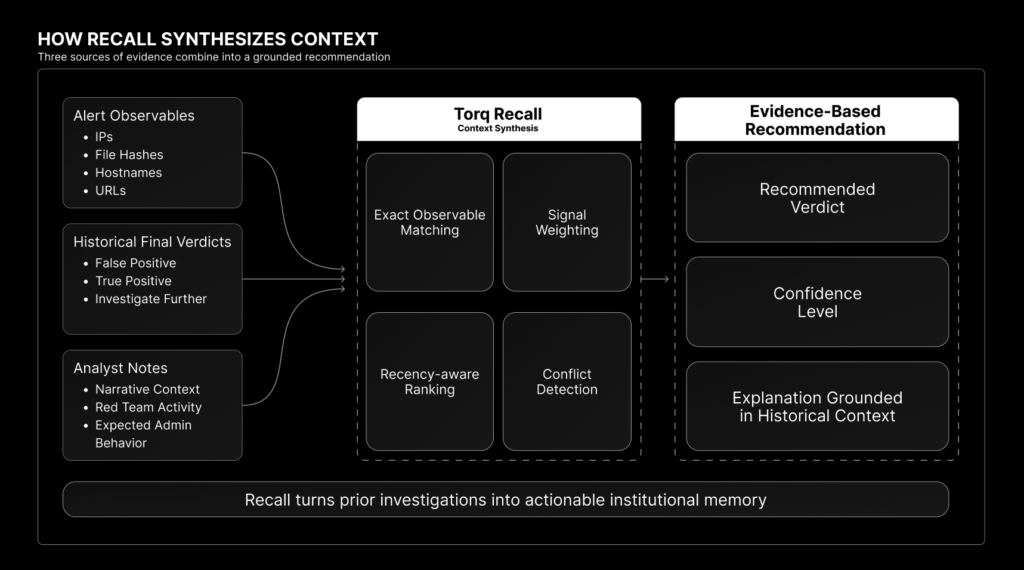
Torq Recall rejects fuzzy precedent matching in favor of Structured Retrieval. Instead of guessing, Recall relies on exact, deterministic overlaps of specific security observables — like IPs, file hashes, URLs, hostnames, or emails — to trigger a historical match. This ensures that every AI-driven triage recommendation is auditable, explainable, and grounded in verifiable evidence from your own environment.
But exact matching is only the first step. Recall also has to understand the signal strength. A match on a rare file hash, unique URL, or unusual email address can carry strong precedent. A match on a common binary like explorer.exe, or a widely shared corporate IP is much weaker. Torq Recall is designed to focus the AI on the security entities that actually matter — not just the ones that happen to overlap.
Deterministic Context Matching: Unlocking the Goldmine
Resolved cases are the raw material for AI SOC memory — the operational record of how your team actually works. Instead of leaving this context buried in closed tickets, Torq Recall seamlessly connects today’s raw alerts with yesterday’s finalized human reasoning.
When a new alert hits, Recall instantly searches your environment’s case history for relevant precedent. It does not treat every historical match equally: cases are prioritized based on exact observable overlap, signal strength, and recency. Because security environments change quickly, Recall applies a time-aware decay factor, allowing fresh resolutions to carry more weight while still preserving older institutional knowledge when the evidence is strong.
Crucially, Recall doesn’t just count past alerts; it analyzes the final resolution decision and the analyst notes.
AI in the Trenches: Handling SOC Chaos
In a real SOC, the data is rarely clean. Alerts arrive with partial context, telemetry is noisy, and human decisions are not consistently captured. Two similar cases may receive different labels, or the analyst’s notes may tell a more nuanced story than the final resolution field. If an AI system is designed in a sterile lab under the assumption of perfect data hygiene, it will inevitably fail when it encounters real-world ambiguity.
Torq Recall was designed not just to find historical matches, but to critically evaluate the quality and consistency of that precedent. Using rigorous LLM-in-the-loop stress testing, the AI was trained on curated case histories that mimic the messiest edge cases in a live SOC.
The guiding design principle was to build an “honest AI” that exhibits calibrated confidence. Instead of blindly forcing a recommendation when data is sparse or contradictory, Recall includes a subagent architecture that is instructed to act like a veteran analyst: it weighs the evidence, spots inconsistencies, and knows exactly when to ask questions.
The system gracefully manages real-world SOC chaos by identifying and adapting to complex scenarios like the ones below.
| Real-World SOC Scenario | What was Encountered | How Torq Recall Handles It |
| Conflicting Precedent | Half of the historical alerts were closed as False Positives, while the other half were escalated as True Positives | Refuses to pick arbitrarily. Recall lowers its confidence score, explicitly flags the split precedent, and recommends the team “Investigate Further” |
| Misleading Labels (e.g., Red Team) | A past case is labeled “True Positive/Malicious,” but the analyst notes state: “Update: Part of a concluded red team exercise” | Prioritizes the narrative context in the notes over the static resolution label, recognizing that the threat is no longer active, and adjusts its recommendation accordingly |
| Severity Mismatches | Historical cases sharing an IP address were Critical-severity attacks, but the new alert is a Low-severity informational event | Highlights the severity mismatch as a key difference, ensuring it does not blindly inherit the escalation precedent of a completely different attack type |
| Weak Signal Overlap | The system finds a match, but it relies on a single, low-fidelity observable (such as a common corporate IP address) | Openly acknowledges the weak precedent, returns a “Low Confidence” assessment, and refuses to force a definitive recommendation |
| Inconsistent Data Entry | An alert is coded with a “False Positive” reason, but the detailed resolution notes describe actively blocking malicious activity | Flags the contradiction between the label and the details, lowering confidence to prevent the SOC from trusting bad data |
To make this behavior reliable, we built a comprehensive testing and evaluation suite based on real-world data, including conflicting precedents, misleading labels, weak observable overlap, severity mismatches, and inconsistent analyst notes.
Recall is evaluated against these scenarios to ensure it surfaces discrepancies transparently instead of hiding them behind a black-box verdict. When the AI is honest about uncertainty and catches inconsistencies in past documentation, it builds the kind of trust analysts need before relying on automated triage.
From Tribal Knowledge to Institutional Memory
Letting the intelligence of your security team disappear the moment a ticket is closed is an architectural flaw that modern SOCs can no longer afford. Torq Recall fixes this by capturing analyst expertise implicitly, turning it into durable AI SOC memory without adding a single click to the workflow.
But this is just the foundational layer of institutional memory. We are currently expanding Recall’s contextual reach beyond closed cases. By integrating directly with the Torq data fabric, the system is evolving to capture deeper organizational context and fetch richer historical signals directly from your alerts. For an AI-native SOC, more context directly translates to better triage quality: the broader the historical data pool, the more precise and reliable the AI’s precedent matching becomes.
Ultimately, this continuous learning layer is being integrated across Torq’s wider product ecosystem, including Socrates — our AI SOC orchestrator. Building a resilient SOC doesn’t mean writing more rigid rules; it means deploying an AI teammate that seamlessly learns from every resolution your team makes.
Torq Recall is one piece of a larger body of work on how we build trustworthy, agentic AI for security operations. Our series on Context, Memory, and Learning in the AI SOC breaks down the architecture, testing methods, and design decisions behind the AI SOC.

Rony Fluk is a Senior AI Engineer at Torq, focused on building AI-native capabilities for modern security operations. He brings deep experience in LLM systems, automation, and agentic AI, designing deterministic, context-aware automation that helps SOC teams preserve institutional knowledge and make faster, more reliable decisions.

Noam Cohen is a serial entrepreneur building seriously cool data and AI companies since 2018. Noam’s insights are informed by a unique combination of data, product, and AI expertise — with a background that includes winning the Israel Defense Prize for his work in leveraging data to predict terror attacks. As the Head of Artificial Intelligence at Torq, Noam is helping build truly next-gen AI capabilities into Torq’s autonomous SOC platform.



