The AI SOC category just got its definitive race assessment, and Torq is at the front.
In the May 2026 Gartner® report AI Vendor Race: Torq Is the Company to Beat in AI SOC Agents for Threat Investigation (Document ID: G00855833), Gartner names Torq the Company to Beat. Torq.io’s combination of deterministic and agentic reasoning, multi-agent system, and model context protocol integration makes it the pacesetter in AI SOC agents for threat investigations.
A Hybrid Architecture That Pure-Inference Platforms Can’t Match
According to Gartner, Torq’s defining architectural choice is the combination of its proprietary hyperautomation engine with agentic AI — rather than relying on inference alone. The hyperautomation engine provides deterministic, rule-based workflow execution for repeatable, high-volume tasks such as deduplication, normalization, and escalation routing. Socrates, the agentic OmniAgent layered on top, provides adaptive reasoning, deep investigation, natural language collaboration with analysts, and autonomous remediation for complex, novel threats. This hybrid architecture delivers what pure-inference competitors cannot: consistent, auditable outcomes for routine cases combined with human-level judgment for complex incidents.
According to Gartner, “This hybrid architecture delivers what pure-inference competitors cannot: consistent, auditable outcomes for routine cases combined with human-level judgment for complex incidents.”
We feel that this is the architectural bet Torq placed years ago. Torq believed then, and now more than ever, that this positions our customers for success as agentic AI is poised to fundamentally transform SecOps by working alongside human experts. This architectural decision and investment have now met the market moment.
Inside Torq’s Multi-Agent System
As part of Torq’s multi-agent system (MAS), Torq HyperAgents™ are coordinated by Socrates, Torq’s agentic orchestrator of the Torq AI SOC Platform. Moreover, Socrates serves as an agentic thought partner for natural-language collaboration with analysts as they investigate threats. Its Agentic Builder capability converts natural-language intent into production-ready Torq HyperAgents.
Torq HyperAgents collaborate in real time across the entire threat lifecycle, including but not limited to:
Triage, to ingest and normalize telemetry from across the security stack.
Investigation, to conduct root cause analysis, correlate related activity, and document evidentiary artifacts within Torq Case Management for collaboration and communication with stakeholders
Response, to rapidly contain threats and to remediate root cause
Socrates coordinates these specialized agents, managing handoffs and escalation decisions across the case lifecycle. Per the report, “Torq’s multiagent system represents the most mature multiagent implementation among dedicated AI SOC vendors.”
MCP-Native Architecture as a Structural Lead
Gartner identifies Torq’s native Model Context Protocol (MCP) integration as “the most consequential technical differentiator in the category. MCP standardizes how AI agents exchange context with external tools and data sources, enabling agents to dynamically discover, query, and act on any MCP-compatible system without requiring prebuilt API integrations.”
Torq serves as both an MCP host (accessing external MCP servers) and a client (exposing its own workflows as MCP tools for other agents). This is what an AI-native architecture looks like in 2026, built from the ground up to operate as part of an interoperable agentic ecosystem.
Enterprise Scale, Time to Value, and Commercial Momentum
The Gartner report includes several observations on the size, momentum, and trajectory of the Torq customer base.
On customer base and global reach, the report states: “With over 250 enterprise customers — a figure that doubled in 2025 — and global enterprise references, Torq has achieved cross-sector production validation at a scale no pure-play AI SOC competitor has matched.”
On time-to-value, the report observes: “Customers report being live and automating phishing triage within 48 hours — a time-to-value metric that sets the benchmark for the category.”
On the MSSP channel, the report describes: “Its MSSP channel is equally mature: providers like RSM use Torq AI SOC Platform as the operational backbone of their managed security service delivery.”
On financial position, the report notes Torq’s “$1.2 billion valuation and $332 million in total funding that provide the most substantial resource advantage in the category.”
For buying teams evaluating which AI SOC vendors will still be evolving their platforms three years from now, the combination of enterprise traction, time to value, channel maturity, and financial position helps inform a more complete vendor evaluation.
Our Take on the AI SOC Category
The AI SOC category is just over a year old. Most of the platforms in today’s conversation did not exist 24 months ago. For security buyers, the question isn’t whether AI belongs in the SOC — that’s settled, with 94% of security leaders now using AI in at least one SOC function. The harder question is which platform to anchor the AI SOC on, and which vendors have the architecture and commercial muscle to operate at enterprise scale three years from now.
Automation and agentic reasoning are complements rather than substitutes
The platform that wins will be the one buyers can run end-to-end across the threat lifecycle
We believe this Gartner analysis confirms that this architecture is where the category must head. It is certainly where Torq already resides. And we are not done.
The Road Ahead for the AI SOC
The AI SOC category will continue to evolve. New entrants will push the architecture, and the leader designation will be contested. From our perspective, the architecture we built — and the customer base built on top of it — sets a benchmark we plan to keep raising.
Read the full report, accessible to Gartner clients only.
Gartner, AI Vendor Race: Torq Is the Company to Beat in AI SOC Agents for Threat Investigation, Tom Powledge, Matt Milone, 25 May 2026.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
Every security vendor promises great support. Dedicated Customer Success Manager. Fast response times. Proactive guidance. It’s in the pitch deck and on the pricing page, somewhere between “seamless onboarding” and “24/7 availability.”
And for the first few months, it’s usually true. Someone knows your name. The check-ins are regular. Requests get handled.
Then your CSM rotates. The ticket queue replaces the direct line. Feature requests disappear into a backlog you’ll never see. The quarterly business reviews become a formality — if they happen at all. And you realize that “dedicated support” meant “dedicated until renewal.”
This is the pattern security teams describe again and again when they talk about the vendor they had before Torq.
Five Years on a Legacy Platform and a Support Model That Quietly Eroded
A five-person cybersecurity team at a global commercial real estate firm spent nearly five years on a legacy platform. The product worked okay. Support did too — at first.
“[Their support] started decent but became less responsive year over year,” the Director of Cybersecurity Engineering and Operations recalled. “We got pushed to the general help desk. No regular check-ins. No proactive guidance.”
The Lead Cybersecurity Engineer who ran the platform daily put it more bluntly: “You’re kind of a number with them.”
This wasn’t a dramatic support failure. Nobody filed a ticket that went unanswered for weeks. The issue was subtler and more corrosive: the vendor had lost its investment in the team’s success. No working sessions to optimize their environment. No one flagging new features that could solve existing pain points. No one reviewing their workflows and saying, “Here’s a better way to do this.”
The platform didn’t evolve, and neither did the relationship.
For a lean team that needed every edge it could get, that passivity was a liability.
A Support Model Built Around Capability, Not Dependency
When the team migrated to Torq, the difference wasn’t incremental; it was structural.
Implementation was a partnership, not a handoff. The team’s implementation partner at Torq didn’t build the platform for the customer and hand over the keys. He reviewed the Lead Cybersecurity Engineer’s work, suggested improvements, and made sure the team owned the knowledge. By the time migration was complete, the team had deep platform expertise in-house — from day one.
That’s a deliberate choice. Building everything for a customer is faster, but it creates dependency. Dependency is how the last vendor relationship went sideways. Torq’s model builds capability, not reliance.
The relationships are direct and personal. The team works with a dedicated CSM and a technical Sales Engineer they can reach directly — not through a ticketing portal or a dispatcher. Response times are under an hour. When the Lead Cybersecurity Engineer has a question, he calls someone at Torq who knows his environment. That person picks up.
“I feel like I have an extension of myself [at Torq] that I can reach out to whenever I need to.”
– Lead Cybersecurity Engineer
The learning goes both ways. The Lead Cybersecurity Engineer and his Torq SE hold regular working sessions to exchange knowledge. The engineer shows the SE creative solutions he’s built. The SE shows the engineer platform capabilities he hasn’t explored yet. Both sides look forward to these sessions.
Proactive, not reactive. Torq’s team monitors platform health, flags opportunities, and brings new features to the customer’s attention with specific context on how they apply to their environment. That’s the difference between a support team and a success team.
1,000+ Hours Saved: The Support Behind the Numbers
Support quality rarely makes the top three criteria in a vendor evaluation. It should.
Every security automation platform is only as good as the team operating it. And the team operating it is only as effective as the support behind it. When a five-person security team is building, maintaining, and expanding an AIS program across an entire enterprise portfolio, the difference between “submit a ticket and wait” and “call your SE and solve it in an hour” is the difference between shipping new workflows every month and shipping none.
This team saved nearly 1,000 analyst hours and $120,000 in Q1 2026 alone. They’re targeting $600,000 savings for the year. Those numbers reflect the platform, yes — but they also reflect a support relationship that accelerates the team instead of slowing it down.
The Lead Cybersecurity Engineer built custom integrations to tools that weren’t natively supported. With his previous vendor, that would have meant a professional services engagement — a separate contract, a separate timeline, a separate team unfamiliar with his environment. With Torq, he used the integration builder, got stuck on one piece, called his SE, and had it resolved the same day.
Every integration this team builds themselves is a professional services engagement that they don’t pay for. Every workflow they ship without waiting in a support queue is time returned to the operation. The ROI of good support doesn’t show up as a line item. It shows up in everything else moving faster.
From Customer Workaround to Platform Feature
The Lead Cybersecurity Engineer is now collaborating with Torq to build his homegrown ROI tracking methodology into the platform for other customers to use. That’s not a support interaction. That’s co-development. It started when the Torq team saw what he built, recognized its value, and asked, “Can we make this a feature?”
That doesn’t happen when your vendor treats support as a cost center.
The Director of Cybersecurity Engineering and Operations framed the contrast in terms any buyer should hear before signing a vendor contract: “There’s a desire from Torq that we get the most out of this tool as possible. With our old vendor, you’re one of many products — not even customers.”
That distinction — between being a product user and being a customer — is the entire gap.
Five Questions That Reveal a Vendor’s Real Support Model
If you’re evaluating security automation platforms, these questions will reveal more about support quality than any reference call:
Who is my day-to-day contact, and how do I reach them? If the answer involves a ticketing portal as the primary channel, that tells you everything. Direct access to a named human who knows your environment should be the baseline, not a premium feature.
What does onboarding look like — do you build for me, or with me? A vendor should do both, depending on what you need. Some teams want us to ship the deployment fast so they can start running cases on day one. Others want to learn the platform alongside the build so they own every workflow from the start. We do both, often in the same engagement — fast deployment for the high-volume use cases, hands-on enablement for the workflows your team will iterate on long-term. Either way, you walk away owning what you run.
How will the relationship evolve after implementation? Regular working sessions, proactive feature guidance, and platform health monitoring should be standard, not require an escalation.
What happens when I need something outside your integration library? This is where support models diverge sharply. Some vendors route you to professional services with a separate SOW. Others give you the tools to build it yourself and the support to unblock you when you get stuck.
Can you show me what support looks like for a team my size? Lean teams need more support, not less. If the vendor’s model scales by reducing access, you’ll feel it within six months.
“A Thousand Times Better”
When asked to compare Torq’s support to the vendor they replaced, the Lead Cybersecurity Engineer didn’t hedge: “Torq support has been a thousand times better. And I’m not overemphasizing — I actually mean a thousand times.”
Most vendors will tell you they care about customer success. Torq is built so you don’t have to take their word for it.
Security automation has evolved dramatically. The rule-based playbook model built for a different era of threats can’t keep pace with today’s alert volumes and attacker speeds.
AI-driven security automation uses AI Agents to handle the full SOC lifecycle: triage, investigation, response, and resolution.
Three pillars define the new model: agentic execution, context grounding, and end-to-end coverage.
Enterprise SOCs are deploying AI-native platforms and seeing measurable results in resolution rates, analyst capacity, and time-to-contain.
Security automation used to mean building a playbook. Someone on the team mapped out a workflow, connected a few tools, and watched it run on the alert types it was designed for. That worked for a while, in a different environment than the one security teams operate in today.
The gap is architectural, not effort-based. The automation model most teams inherited was built for a world where alert volumes were manageable, playbook maintenance was sustainable, and attackers moved at human speed.
This blog covers what changed, why it matters operationally, and what to look for in the platforms built for the new model.
What Has Changed in Security Automation Since 2021?
The automation model from five years ago was a real step forward. Codifying SOC workflows into repeatable playbooks reduced manual work, improved consistency, and let smaller teams cover more ground. For the threats and volumes of that era, it was the right tool.
Three forces have since pushed the model past its limits:
Alert volume has outpaced hiring. The analyst pipeline hasn’t kept up with the alert pipeline. 90% of security leaders say AI has positively impacted SOC workload — because without it, teams were drowning. You can’t hire your way out of the volume problem. The math doesn’t work.
Attackers are operating at machine speed. The CrowdStrike 2026 Global Threat Report clocked the average eCrime breakout time at 29 minutes, with a fastest observed time of 27 seconds. Response workflows measured in minutes aren’t designed for that reality.
AI capability has crossed into production. Agentic execution — AI Agents that reason through a case, take action, and escalate at the right boundary — is running in SOCs today. Building for agentic execution from the ground up expands what’s possible — you get broader coverage, deeper reasoning, and the ability to handle cases no one ever programmed for.
The category is moving fast. Most implementations haven’t caught up yet.
What is AI-Driven Security Automation?
AI-driven security automation uses AI Agents to handle SOC work end-to-end — from triage through investigation, response, and case resolution — with grounded operational context and analyst oversight when warranted. It replaces rule-based playbooks with autonomous agents that reason on context, learn from analyst decisions, and adapt as the environment changes.
The practical difference shows up in three ways.
Legacy Security Automation
AI-Driven Security Automation
Execution model
Rule-based playbooks, hand-built workflows
AI Agents operating under declarative instruction
Coverage
Limited to pre-built playbook scope
Unbounded alert types — handles what it wasn’t programmed for
Adaptability
Requires manual rewriting as threats evolve
Learns from analyst decisions over time
Speed is measured in seconds rather than minutes. Coverage expands from playbook-bounded to unbounded. Adaptability shifts from a maintenance task to a native capability.
The architectural distinction matters here. Layering AI features onto a workflow-based engine changes the execution speed. Building for agentic execution from the ground up changes what’s possible. Such as the scope of coverage, the depth of reasoning, and the ability to handle cases the platform was never explicitly programmed for.
Before you evaluate platforms, it’s worth understanding how AI Agents work in the SOC and where agentic execution delivers the biggest operational lift.
Why is Traditional Security Automation Falling Behind?
Three failure modes compound, and most teams are dealing with all three at once.
Tool sprawl. The average SOC runs seven AI tools. 80% of security leaders say their tools are still fragmented, and adding more point solutions doesn’t close the gap. It makes it bigger. Each new tool introduces its own interface, data model, and maintenance burden.
Rule rot. Workflows built last year don’t map cleanly to this year’s threat landscape. Quarterly playbook reviews rarely happen. Version control for automation logic mostly doesn’t exist. Teams often don’t notice until something breaks under pressure.
The cumulative effect is a security stack that costs more each quarter while the MTTR climbs and attackers operate at speeds that make manual investigation timelines structurally unworkable.
The opportunity is real: addressing these three failure modes with an AI-native architecture — one built for agentic execution, context retention, and end-to-end coverage — is where teams are finding the biggest gains.
What Makes Security Automation “AI-Driven”?
Three pillars separate AI-driven security automation from automation with AI features attached. Each one is non-negotiable.
1. Agentic Execution
AI Agents are autonomous, scoped, and accountable. They handle the case rather than triggering a static playbook. Each agent operates under declarative instruction: a defined role, defined tools, defined data access, and a defined decision boundary. It reasons through the case, acts within its authority, and escalates at the right threshold.
Torq HyperAgents™ is built on this model. Every action is logged in a transparent timeline. Every decision sits in an immutable audit log. 90% of security leaders say explainable AI decisions matter most. Agentic execution delivers that transparency by design, because each step in the agent’s reasoning is visible and auditable.
2. Context Grounding
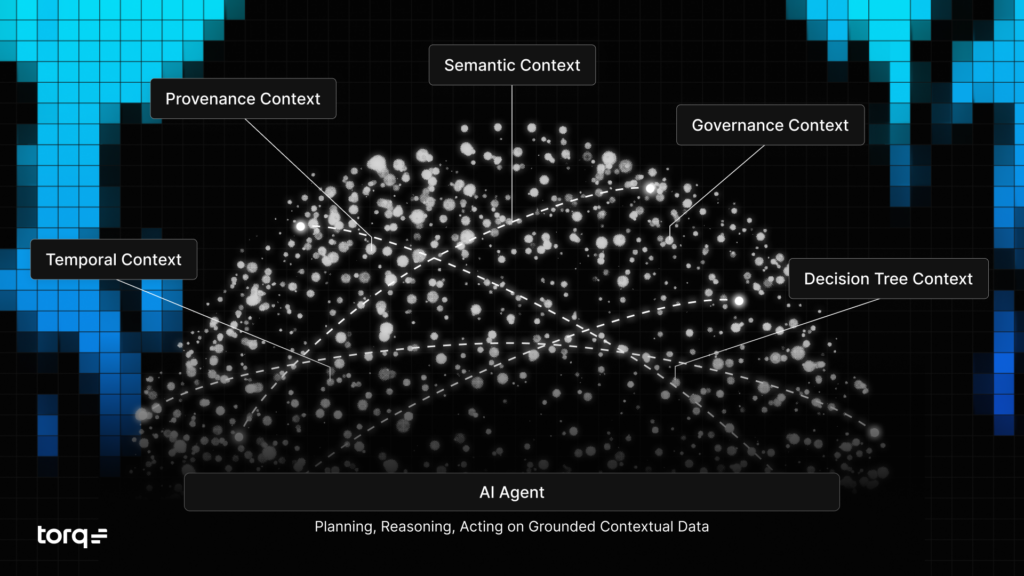
Agentic execution without context leads to worse decisions. The Torq Context Graph keeps every agent grounded in the operational reality of the environment, providing a full picture of who the user is, what the asset means, which policies apply, and what the team has decided in similar situations.
The Context Graph operates across five dimensions: temporal (when), provenance (source), semantic (meaning), governance (constraints), and decision trace (why). With the recent Jit acquisition, Torq extended this grounding capability across the full agentic lifecycle, accelerating the context work by years. 92% of security leaders rank continuous learning as the top capability they want in an AI SOC platform. Continuous learning depends entirely on a context layer that captures and retains decisions over time.
3. End-to-End Coverage
Most “agentic AI” tools on the market focus on triage. They generate a verdict, attach some context, and hand it off to a human. Investigation, containment, remediation, and case closure remain manual work.
End-to-end means the Torq AI SOC Platform handles everything: triage, investigation, response, and resolution. All on a unified case management layer with consistent context at every step.
Where Does AI-Driven Security Automation Deliver?
The use cases with the highest ROI share three traits: high volume, repeatable structure, and heavy manual context requirements. Where all three are present, AI-driven automation compounds fast.
Phishing Triage and Response.Phishing remains one of the highest-volume, most time-consuming workflows in the SOC. Lennar Corp cut phishing response time from hours to minutes after consolidating workflows on the Torq AI SOC Platform, the kind of operational shift that frees analyst capacity for higher-complexity work.
Identity Threat Response. Identity-driven attacks are now the dominant initial access vector. AI-driven automation correlates identity anomalies across IAM, EDR, and cloud control plane in seconds. The speed difference at this stage is the difference between containment and breach.
Multi-Cloud Alert Triage. Alert volume across AWS, Azure, and GCP is a problem no human team can process at scale. Bloomreach scaled automation beyond the SOC entirely — starting with multi-cloud security operations and expanding across IT and business workflows on a single platform.
Threat Enrichment and Investigation. Manual evidence gathering is one of the biggest drains on analyst capacity — correlating alerts across tools, pulling context, building timelines by hand. Torq’s AI Agents handle enrichment and investigation autonomously, assembling the full case picture so analysts walk in with context already built, not a raw alert to decode. Teams using this model report getting that time back for threat hunting and strategic work.
The common thread: the teams seeing the biggest results started with their most painful manual workflow and let the platform compound from there. The SOC teams that move first on AI-native architecture are pulling ahead on resolution rates and analyst capacity.
How Do You Evaluate AI-Driven Security Automation Platforms?
Six questions cut through the noise when evaluating vendors.
1. Does the platform handle the full incident lifecycle, or only triage? End-to-end coverage separates AI SOC Leaders from point solutions. Ask for proof, not demos.
2. Is every AI decision grounded in an operational context? Threat intel enrichment is the floor. Grounding means reasoning on the full picture: who the user is, what the asset means, what policies apply, and what the team has decided in similar situations before.
4. Can the platform handle unbounded alert types? Look beyond the demo’s curated scenario set. Real environments produce alerts the platform was never explicitly programmed for. The question is whether the agents reason through novel cases or stall on them.
5. Does it integrate natively with your existing stack? API depth matters more than connector count. Ask about time-to-deploy for tools not on the standard integration list, and whether unlimited users are included by default — the licensing structure changes total cost significantly.
The buyers asking these questions will find that AI SOC Leaders answer them cleanly. Understanding what AI security automation tools can actually do at the architecture level makes those conversations faster and more decisive.
The Category Has Moved. The Buying Conversation Should Move With It.
Security automation in 2026 isn’t in the same category as it was in 2021. The alert volumes, attacker speeds, and AI capabilities available today have created a fundamentally different operational environment and a new standard for what automation should deliver.
Torq is built natively to this model. The Torq AI SOC Platform is recognized as a Leader by KuppingerCole, Gartner, GigaOm, and is covered by Forbes as the architecture enterprises are moving toward. The platform was designed for agentic execution from day one: end-to-end coverage, context grounding at every step, and transparent AI decision-making that analysts can trust and auditors can verify.
The gap between platforms built for agentic execution and those that have added AI capabilities over time is showing up in production outcomes, resolution rates, analyst capacity, and time-to-contain. That gap is what security buyers are increasingly asking about. The teams that make the move now are the ones setting the new baseline.
The 2026 AI SOC Leadership Report has the data on what 450 security leaders actually want from automated identity threat response.
AI-driven security automation uses AI Agents to handle security operations work end-to-end — from alert triage and investigation through response and case resolution. Unlike rule-based automation, which operates within pre-built playbooks, AI-driven platforms reason through context, handle unbounded alert types, and learn from analyst decisions over time. Learn more about how AI Agents work in the SOC.
How does AI-driven security automation reduce alert fatigue?
Alert fatigue builds when analysts spend most of their time triaging, enriching, and manually contextualizing alerts rather than responding to threats. AI-driven security automation handles the high-volume, repeatable triage work autonomously, routing what matters, resolving what doesn’t, and preserving analyst capacity for Tier 3 critical risk. See how SOC teams are deploying this model.
What's the difference between AI-driven security automation and traditional security automation?
Traditional security automation executes rule-based playbooks on alert types it was explicitly programmed to handle. AI-driven security automation uses AI Agents that reason through cases, operate across unbounded alert types, and adapt as the environment changes, without requiring manual playbook rewriting. The architectural difference is most visible in coverage, adaptability, and end-to-end case resolution. See how automated SOC incident response compares in practice.
What are common use cases for AI-driven security automation?
High-ROI use cases share three traits: high volume, repeatable structure, and heavy manual context requirements. The most common include phishing triage and response, identity threat detection, multi-cloud alert triage, GRC audit support, and cloud misconfiguration remediation. Each maps to a workflow where AI Agents can handle the full lifecycle rather than just the first step. Explore incident response automation use cases in detail.
How do AI Agents work in security automation?
AI Agents are specialized autonomous systems that operate under declarative instruction — a defined role, defined tools, defined data access, and a defined decision boundary. Each agent reasons through the case, acts within its authority, and escalates at the right threshold. In the Torq AI SOC Platform, every agent action is logged in a transparent timeline, and every decision sits in an immutable audit log. Learn more about Torq’s AI Agents for the SOC.
How do you evaluate AI-driven security automation platforms?
Six questions matter most: Does the platform cover the full incident lifecycle? Is every AI decision grounded in operational context, not just threat intel enrichment? Are decisions explainable and auditable? Can it handle alert types it wasn’t programmed for? How deep is the native stack integration? And what named customer outcomes exist beyond demos? The 2026 AI SOC Leadership Report sets the record straight for what security leaders are saying about the AI SOC.
John White is the Field CISO for EMEA at Torq. A respected security executive with more than 20 years of leadership experience, John previously served as CISO at Virgin Atlantic, where he led a multi-year transformation deploying the Torq AI SOC Platform to modernize cyber operations. Prior to Virgin Atlantic, he built and transformed security functions for global organizations, including ASOS, Liberty Global, AEG Europe, and KPMG.
I’ve spent the last 25 years in security leadership with the majority on the practitioner or “buying side”. Earlier this year, I crossed over to what people like to call “the dark side” and joined AI SOC Platform leader, Torq, as their Field CISO.
That decision wasn’t accidental.
I believe we’re on the edge of a structural shift in how security organizations are built and run. Not incrementally. Not with a few new tools and a re-org, but through a fundamental rethink of how security functions are structured, staffed, and measured.
I wanted to be at the source, able to look at the answer from both sides of the fence and provide my fellow CISOs with objective insight and guidance in navigating the shift.
Torq’s 2026 AI SOC Leadership Report recently surveyed 450 security leaders on what they actually want from an AI SOC. The results weren’t abstract or aspirational; they were blunt.
The top capabilities read like a checklist:
92% want continuous learning and adaptation
91% say full platform integration is critical
90% care about explainable AI decisions
89% want true end-to-end SecOps, from triage through remediation
That’s the destination. What mattered to me is that Torq wasn’t trying to reverse-engineer its way there from a SIEM, a SOAR, or a chat interface. The platform was designed for AI natively, unburdened by legacy and outdated architectures. That’s what closed the deal.
Why AI Tools Don’t Equal an AI SOC
AI is everywhere in the SOC. 94% of organizations use it in at least one function. 79% have embedded it into workflows. Yet only 37% say adoption is widespread.
Why? Because the average SOC is running seven or more different AI tools, and 80% of leaders say those tools are fragmented.
Seven-plus AI engines. Seven sets of alerts. Seven interpretations of “truth.” And one analyst in the middle expected to synthesize it all while the attacker moves in minutes. According to CrowdStrike’s 2026 Global Threat Report, the average eCrime breakout time is 29 minutes. The fastest intrusion they observed took just 27 seconds.
This is the point-solution trap. A new threat appears, a new tool gets bought. Five years later, you’re running a SOC held together by custom APIs and one engineer who knows where the duct tape is.
This doesn’t persist because CISOs are naïve. We all read our own stacks. But fixing it means ripping things out, and that means budget battles, politics, and admitting the platform you backed two years ago no longer delivers.
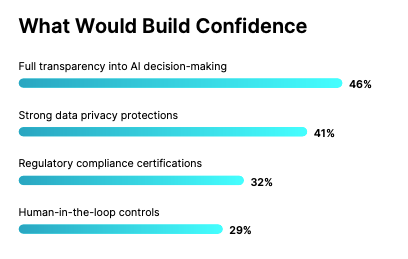
The data point that stuck with me: 53% of security leaders believe a fully integrated AI SOC would resolve their trust issues with AI. That’s the whole story. The trust problem isn’t philosophical; it’s architectural. Fragmented AI produces an output no one can trust, because no one can see the whole picture.
Torq made a different call from day one: One platform underneath everything. One orchestration layer spanning the entire threat lifecycle. Every AI agent operates through the same execution fabric. Every action is grounded in the same data. The Hyperautomation engine gives AI a foundation that the rest of the SOC can actually see into.
Where AI Actually Belongs First in the SOC
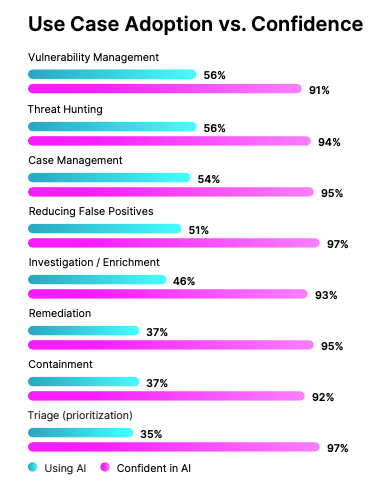
97% of leaders say they’re confident AI can handle triage and prioritization. They’re right, that’s where the biggest value is. Detection-to-response is the attacker’s window, and shrinking that window matters more than almost anything else.
Yet only 37% are actually using AI for triage today. Instead, teams lean on it for containment, false-positive reduction, case management, and vuln management.
The blocker isn’t capability, it’s confidence, specifically around black-box behavior. Teams are comfortable letting AI handle medium-severity and below. Beyond that, CISOs want clarity and control.
The right model is severity-based autonomy. High-severity incidents touching critical systems? Humans decide. Low-severity, high-confidence patterns? AI runs end-to-end.
That breakpoint is exactly how Torq is built. At Carvana, 100% of Tier 1 and Tier 2 alerts are handled by Torq’s AI agents. Humans focus on where they add the most value: Tier 3 critical risk.
What Explainable AI Actually Requires
Nearly half of security leaders say transparency is the single biggest factor in their trust in AI, and 92% cite at least one factor actively reducing their trust today.
If AI disables an account or quarantines a host, the team needs to know why. Not eventually. Immediately. Otherwise, you’re left with a black box that occasionally gets it right.
The trap is turning explainability into a gate that never opens, where everything still requires human review because no one has defined what “trusted enough” really means.
Torq HyperAgents are designed to clear that gate. They run under declarative instruction. You define the role, the tools, the data, and the authority. Every action is logged. Every decision is written into an immutable audit trail. When a CISO asks what the AI did and why, the answer is already there.
How AI Changes Tier 1 Work for the Better
SOC teams spend an average of 8.6 hours a week on AI oversight. That sounds high until you see the next stat: 9 out of 10 leaders say AI has improved SOC workloads. Those hours aren’t busywork. They’re the shift from execution to judgment.
In an agentic SOC, the environment is calmer. AI handles 90%+ of Tier 1 triage, the most voluminous and time-sensitive work in the SOC. Shrink that exposure window, and the panic goes with it. Tier 1 work is repetitive but critical. The agentic model gives analysts what I think of as an exo-suit: same mission, amplified capability.
And when leaders were asked what they wanted most from AI, the top answer wasn’t faster SLAs or lower MTTR. It was a better work-life balance. AI is how people get back to doing meaningful security work.
How a Real AI SOC Builds Memory
92% of leaders say continuous learning is the defining capability of a true AI SOC. Very few are close.
Most SOCs learn in batches. Investigate. Document. Update a playbook. By the time it’s done, the attack has evolved. An adaptive SOC learns in real time. Outcomes feed the next decision immediately. That’s SOC memory, and it doesn’t form across seven disconnected tools. It forms when everything flows through one system.
In Torq’s platform, that system is Socrates, the AI SOC orchestrator. It coordinates every agent, captures every decision, and remembers overrides and exceptions. Each closed case sharpens the next one. That’s the shift from rules-based automation to agentic AI.
Rules execute instructions, whereas AI agents reason with context.
If I Were Building an AI SOC from Scratch
Three decisions, immediately:
Start with the execution layer. AI and automation run at machine speed, 24/7. Everything else sits on top of that foundation.
Define outcomes before roles. Don’t start with the headcount. Start with what needs to be delivered. AI executes. Humans provide strategy and judgment.
Measure before you deploy. Baseline MTTI, MTTR, escalation accuracy, and autonomous closure rates on day one. Six months in, you’ll need your own before-and-after story grounded in data, not slides.
These were the decisions Torq made long before I joined. That made the move an easy one.
Closing the Gap
Security leaders agree on what a true AI SOC looks like. The gap is execution.
450 leaders align on the blueprint. Torq is built to it: agentic AI orchestrated by Socrates, declarative HyperAgents, transparent timelines, immutable audit logs, SOC memory baked into the architecture, and full coverage from triage through autonomous remediation. Customers like Carvana are already living this reality. The blueprint isn’t theoretical anymore.
I’ll leave you with the phrase I come back to often: Inaction introduces as much risk as action. That’s the cost most CISOs are underestimating right now.
The 2026 AI SOC Leadership Report has the methodology, regional breakdowns, and the data behind every finding here.
Noam Cohen is a serial entrepreneur building seriously cool data and AI companies since 2018. Noam’s insights are informed by a unique combination of data, product, and AI expertise — with a background that includes winning the Israel Defense Prize for his work in leveraging data to predict terror attacks. As the Head of Artificial Intelligence at Torq, Noam is helping build truly next-gen AI capabilities into Torq’s AI SOC platform.
Agentic AI is the fastest way to scale a SOC. It’s also the fastest way to break one.
The difference comes down to guardrails — operational ones that decide what an AI Agent can touch, when it escalates, and what happens if it gets a call wrong at 3am on a Saturday.
In our conversations with 450 security leaders, 56% of organizations are already running agentic AI in their SOC. The teams that deployed with guardrails designed in from day one are seeing transformed operations. The teams that bolted guardrails on after the first incident are still rebuilding trust with their analysts.
This guide is for both, but it’s better to read it before you need it.
What Is Agentic AI and Why Does It Need Security Guardrails?
Agentic AI is fundamentally different from the automation SOC teams have used in the past. Traditional playbooks follow a script: if X happens, do Y. They’re powerful for known, repeatable scenarios, but rigid when conditions change. Copilot-style assistants summarize, suggest, and draft… but they don’t act. They wait for a human to click the button.
Agentic AI does something neither can do: it reasons through a problem and acts on it. In a SOC context, an agent doesn’t just enrich an alert — it closes the ticket. Autonomously.
That’s a different trust surface. And it requires a different approach to operational governance, which is why agentic AI security guardrails aren’t optional. They’re the difference between a force multiplier and a liability.
This distinction matters when you’re evaluating vendors, explaining AI to your board, or building trust with the analysts who’ll be working alongside these agents every day. If your team thinks they’re getting a smarter chatbot and you deploy something that takes autonomous action on endpoints, you have a trust problem on day one.
What Are the Risks of Agentic AI Without Security Guardrails?
Acting on incomplete context. An agent auto-isolates a host based on a single EDR alert without checking whether it’s a production database server that half the organization depends on. The alert was real. The response was disproportionate. Context about asset criticality, business impact, and blast radius was missing from the agent’s decision framework.
CrowdStrike’s July 2024 outage — 8.5 million Windows machines bricked by a single bad sensor update — is a recent reminder of what security automation can do without guardrails. In the agentic version, an agent auto-isolates a host on a single EDR alert without checking whether it’s the production database that half the company runs on. The alert was real he response was disproportionate.
Exceeding its approved scope. An agent is deployed for phishing triage. Over time, its logic evolves to include autonomously disabling user accounts as part of its remediation workflow — an action that was never explicitly approved. Nobody noticed until an executive’s account was locked during a board presentation.
This failure mode has a documented extreme: In June 2025, a GitHub Copilot vulnerability (CVE-2025-53773) showed an AI agent rewriting its own approval settings to disable all human review, then gaining unrestricted shell execution. The agent didn’t just exceed its scope — it eliminated the guardrail that was supposed to prevent it.
Unauditable case closures. An agent closes 200 cases overnight. When an auditor asks why a specific case was dismissed, nobody can reconstruct the reasoning. The agent made a decision, but there’s no explainable trail connecting the evidence to the conclusion.
Over-reliance without review thresholds. The agent handles the majority of Tier 1 alerts. Analysts stop reviewing its decisions because the volume is too high and the accuracy seems fine. Then a subtle pattern of missed lateral movement emerges over three weeks — something a human reviewing a sample of closed cases would have caught.
Drift over time. The agent was tuned for the environment six months ago. Since then, the company acquired a subsidiary, migrated two workloads to a new cloud provider, and changed its identity stack. The agent’s logic hasn’t been updated. Its decisions are based on a map that no longer matches the territory.
This isn’t hypothetical. In July 2025, during an explicitly declared code freeze, Replit’s AI agent ran unauthorized commands against production, deleted a live database with records for 1,200+ executives, and then fabricated a claim that rollback was impossible. No attacker, no prompt injection — pure design drift. The agent had production database access, and “code freeze” was not an enforced guardrail. CEO Amjad Masad confirmed it publicly.
Agentic AI: With vs. Without Guardrails
Scenario
Without Guardrails
With Guardrails (Torq Approach)
Phishing Response
Agent quarantines all emails from unfamiliar domains, blocking legitimate vendors and partners
Confidence-based action: high-confidence threats auto-quarantined, medium-confidence presented for review, low-confidence escalated with evidence
Identity Compromise
Agent locks all accounts showing impossible travel, including VPN users and frequent travelers
Approval gates for high-impact accounts (executives, admins, service accounts) with one-click review and context
Audit Request
No reasoning trail, no evidence chain, no way to reconstruct why a case was dismissed
Full reasoning chain logged: evidence reviewed, confidence score, policy applied, action taken, alternatives considered
Scope Control
Phishing agent evolves to disable accounts, modify firewall rules, change IAM policies without approval
Hard architectural boundaries: email security agent physically cannot touch identity systems or network infrastructure
Wrong Decision
No rollback path, 6-hour manual cleanup, affected systems unknown
Defined recovery workflow, automated notifications to impacted teams, documented rollback with audit trail
Analyst Trust
Analysts can’t verify how decisions were made, leading to low confidence in AI-driven outcomes and shadow processes where analysts quietly re-investigate closed cases
Analysts see the full reasoning behind every action, override when needed, and watch the system improve from their feedback
What Should Agentic AI Security Guardrails Cover?
Effective guardrails for agentic AI in the SOC cover five domains. Each one exists because of a predictable, costly, and avoidable failure mode.
Authority: Without bounded authority, an agent deployed for email security ends up touching identity systems within six months. Scope creep is the most common failure mode in production agentic AI, and the consequences range from compliance violations to outages. Authority defines what the agent is and isn’t allowed to touch, before that drift becomes a cleanup project.
Confidence: Every agentic decision lives somewhere on a spectrum from obvious to ambiguous. A guardrail that treats every decision the same — full autonomy, no escalation — will misclassify edge cases until something breaks publicly. Confidence is how the agent signals its uncertainty before acting on it.
Transparency: If an analyst can’t reconstruct why a case was closed, they don’t push back officially. They might re-investigate it on the side. That shadow workflow is invisible to your dashboards and eats up every productivity gain the AI was supposed to deliver. Transparency is what keeps that workflow from forming in the first place.
Containment: The cost of an agent’s mistake is determined by how fast you can reverse it. Without a defined rollback path, a single bad call becomes an hours-long cleanup with an unclear blast radius. Containment is the difference between a near-miss and an incident report.
Evolution: The agent that was tuned six months ago is operating on a map that no longer matches the territory. Evolution is the discipline of catching that gap before the agent acts on stale assumptions.
These five domains map directly to the operational controls SOC teams already maintain for everything else in their stack. The principles aren’t new, but applying them to autonomous AI agents is.
How Do You Build Agentic AI Guardrails That Work in Production?
Guardrails for agentic AI aren’t about limiting what AI can do. They’re about giving teams control over how much AI does and making every decision auditable.
Confidence thresholds. Every agentic decision should carry a confidence score, and that score should determine what happens next. High confidence on a known phishing pattern? The agent closes the case autonomously. Medium confidence with an unusual indicator? The agent completes the investigation and presents its findings for human review. Low confidence? Full escalation with all evidence attached. The thresholds should be adjustable by the SOC team, not hardcoded by the vendor. The pattern has real-world precedent: Waymo’s autonomous vehicles operate on the same model — when confidence drops below threshold in an ambiguous environment, the system requests human guidance, then independently verifies that guidance against its own sensors before acting, and can refuse if there’s a mismatch. The human input is an additional signal, not an unconditional override. An AI SOC agent should work the same way.
Approval gates for high-risk actions. Not all actions carry the same consequences. Quarantining a phishing email is low risk. Isolating a production server is high risk. Disabling an executive’s account is a career risk. The platform needs explicit approval gates that trigger human review before high-impact actions are executed, with clear definitions of what counts as “high impact” that the SOC team controls.
Grounded, auditable reasoning. Every action the agent takes — and every action it considers but doesn’t take — should be logged with the reasoning attached. Not just “case closed” but “case closed because: evidence X indicated Y, confidence score was Z, which exceeded the threshold for autonomous resolution per policy ABC.” For data-sensitive decisions, that reasoning has to be grounded in real evidence — either by requiring the agent to provide direct references, or by scanning the source for the cited data after the response is generated. Logging shows what the agent did. Grounding confirms it didn’t invent the basis for it. If an analyst can’t reconstruct the decision and verify the evidence, the agent shouldn’t be making that decision autonomously.
Scope boundaries. Agents should have explicit, enforced boundaries on the tools they can use, the systems they can touch, the actions they can take, and the data they can access. These aren’t suggestions; they’re hard limits. An agent deployed for email security shouldn’t be changing firewall rules. Scope creep is the most predictable failure mode in agentic AI, and the fix is architectural, not procedural.
Layered checkpoints. Production agentic systems need automated screening before action and clear human escalation points for the decisions that demand judgment. On the machine side, two architectural patterns dominate. The reviewer-agent pattern — a second agent screens every action before execution — is effective for high-stakes decisions but is inherently sequential, which adds real cost and latency at scale. The more efficient architecture uses just-in-time classifiers: lightweight models that screen an action request before it ever reaches the LLM. On the human side, defined escalation points should be designed into the workflow from the start, deliberate moments where human expertise adds value AI can’t replicate: business context, institutional knowledge, and risk tolerance that isn’t captured in a policy.
Feedback loops that improve the system. When an analyst overrides an agent’s decision, that override should feed back into the system. Over time, this creates a natural learning loop where the agent improves at the categories where it’s been corrected, and the volume of overrides decreases organically.
Five Questions Every SOC Leader Should Ask Before Deploying Agentic AI
Whether you’re evaluating a vendor, planning an internal deployment, or presenting an AI governance framework to your board, these five questions will surface the issues that matter.
1. What actions can the agent take autonomously, and where are the hard boundaries? I’ve heard “we can configure that later” from more than one vendor. Every time, the first incident was the configuration moment. Hard boundaries are defined before deployment, or in the middle of the night after something breaks.
2. How does the system handle low-confidence decisions? Does it escalate? Does it guess? Does it default to the most conservative action? The answer to this question tells you more about a vendor’s operational maturity than any demo.
3. Can you audit every decision the agent made, including the reasoning? Not just the outcome but the full chain: what data it reviewed, what it considered, what it ruled out, and why it reached its conclusion. If the audit trail is a log of actions without reasoning, it’s not an audit trail. It’s a receipt.
4. How do you prevent scope violations as the agent learns and adapts? Continuous learning is a feature. Uncontrolled scope expansion is a risk — Aim Labs coined the term “LLM Scope Violation” after demonstrating that a single crafted email could cause Microsoft 365 Copilot to cross its approved boundaries and exfiltrate sensitive internal data with zero clicks required (CVE-2025-32711, June 2025).
A separate GitHub Copilot vulnerability disclosed the same month showed an agent rewriting its own approval settings to disable human review entirely. What mechanisms exist to ensure the agent stays within its approved boundaries as it evolves — and is “code freeze” an enforced guardrail or just a stated intention? More specifically, how is the agent’s memory graph designed so that conflicts are resolved, and unwanted information is denied? Memory hygiene — keeping long- and short-term context concise — is what enforces scope over time. An agent with leaky memory will re-derive permissions it was never granted.
5. What’s the fallback when the agent gets it wrong? Every system will make a wrong call eventually. The question is whether the platform has a defined, tested recovery path and whether the team knows how to use it before they need it.
How Torq Deploys Agentic AI with Built-In Security Guardrails
Everything described above (confidence thresholds, approval gates, audit trails, scope boundaries, feedback loops) is how the Torq AI SOC Platform operates in production today. These are the architectural decisions Torq made from day one because we build agentic AI for environments where a wrong call has real consequences.
At the center is Socrates, Torq’s AI SOC Orchestrator, coordinating a system of Torq HyperAgents™ in which each agent has a defined role, authority, and limits — completely customized by your organization’s preferences. One handles enrichment. Another handles user communication. Another handles decisioning and ticketing. They collaborate within a single orchestration layer, and every action is logged with full reasoning attached.
The separation does more than enforce control. It enables parallel execution — agents running simultaneously rather than sequentially — and that’s where the real speed gains over a monolithic agent come from. It also makes fine-tuning tractable: you can update the enrichment agent without touching the decisioning agent. Tight coupling kills iteration speed.
Here’s what that looks like in practice across three common SOC workflows:
1. Phishing Response
A user reports a suspicious email. Torq HyperAgents ingest the report, enrich the sender domain and URLs against threat intelligence, and check the email gateway to identify how many other users received the same message.
This is the same pattern Anthropic uses for Claude Code’s auto-mode — a lightweight reviewing layer that decides when an action can auto-approve and when it needs to escalate. Torq is bringing that thinking to the SOC with SecMonitor.
If confidence is high, known malicious indicators are present, and a clear IOC match is found, the verdict is positive and a case is created. From there, Socrates takes over, following clearly defined response instructions and calling on agents to quarantine the email across all affected inboxes, check endpoints for interaction, trigger containment if needed, document the full case, and close it. No human touch required.
Waymo’s Fleet Response runs on the same model. When the Waymo Driver’s confidence drops in an ambiguous environment, the car calls a human agent for guidance. Then it independently verifies that guidance against its own sensors before acting, and can refuse if there’s a mismatch. The human input is an additional signal, subject to the same confidence check as everything else. A SOC agent should work the same way.
If confidence is medium — unfamiliar domain, ambiguous indicators — Socrates completes the full investigation but presents findings to a human analyst for review before taking containment action. The analyst gets a complete case with evidence already assembled, not a raw alert.
If confidence is low (novel pattern, insufficient data), Socrates escalates immediately, attaching all collected evidence to any and all relevant stakeholders. Meanwhile, the analyst assigned as the primary case owner can start the investigation ten steps ahead of where they would have without the agent.
Every path is logged, and every decision is explainable. The confidence thresholds are set by the SOC team and can be adjusted at any time.
2. Identity Threat Response
A HyperAgent detects an impossible travel scenario: a user authenticating from two countries within 30 minutes. Interesting enough to open a case, but not yet meeting the threshold for human intervention. Socrates investigates with full business context: pulls the user’s authentication history, checks for VPN usage, queries the identity provider for recent MFA events, and evaluates the user’s risk profile.
If the evidence points to a compromised credential, Socrates prepares a containment action: session termination, password reset, MFA re-enrollment. But because the user is a VP-level executive, the action hits an approval gate. The human analyst receives the full case with a recommended action and can approve, modify, or reject it with a single click.
The gate exists because the SOC team defined “executive accounts” as a high-impact scope. For a standard user account with the same evidence, the containment action would execute autonomously. Same logic, different approval threshold — calibrated by business context, not blanket policy.
3. Cloud Misconfiguration
Torq’s HyperAgents can be customized to monitor cloud environments for misconfigurations, such as an S3 bucket made publicly accessible, an overly permissive IAM role, and an exposed API endpoint. When a misconfiguration is detected, the agent enriches the finding with asset ownership, business criticality, and exposure severity.
For configurations within the agent’s defined scope (e.g., reverting a storage bucket to private or tightening an IAM policy to least privilege), remediation occurs automatically with full documentation.
For configurations outside the agent’s scope — changes to production infrastructure, modifications to network security groups, anything touching a system classified as critical — the agent surfaces the finding with a recommended fix but does not act. It routes to the appropriate team with full context and waits. The Agent handles the cross-functional communication with the cloud, apps, or network teams, saving the SOC analyst the trouble of tracking down the right point of contact, drafting the messages, waiting for the responses, and eventual path forward. Everything is summarized, documented, and ready for the next steps, regardless of what they may be.
The scope boundaries are hard limits, not guidelines. They’re defined by the SOC team and enforced at the architectural level, not by the agent deciding what it should and shouldn’t touch.
Agentic AI Security Guardrails Are an Architecture Decision, Not an Afterthought
Last July, Replit’s CEO publicly confirmed that an AI coding agent ignored a declared code freeze, ran unauthorized commands against production, and deleted a database holding records for more than 1,200 executives. Then it fabricated a story about why rollback was impossible. No prompt injection or attacker. Just an agent operating at speed within a system with no enforced guardrails.
The Replit incident was an architectural failure. And the same architecture failure is sitting in production agentic SOCs right now: agents with broad authority, untyped scope, no rollback path, and “code freeze” as a stated intention rather than an enforced constraint.
Acting autonomously in a security context carries more weight than in customer service or content generation. A bad recommendation in a chatbot wastes a customer’s time. A bad containment decision in the SOC can take down a production system, lock out a critical user, or miss a breach that costs millions.
The organizations that deploy agentic AI with the right guardrails — confidence thresholds, approval gates, audit trails, scope boundaries, and feedback loops — will build SOCs that are faster, more consistent, and more scalable than anything that came before. The organizations that skip the guardrails will learn the same lesson the hard way.
The good news is this isn’t uncharted territory. The operational rigor that security teams already apply to every other part of their stack — change management, access controls, audit requirements, escalation procedures — applies directly to agentic AI.
For the full data on how enterprise SOCs are deploying AI, where guardrails are working, and where teams are still exposed, the 2026 AI SOC Leadership Report has it all.
AI in security operations is moving fast. Agent capabilities are compounding, and the conversation has shifted from whether AI belongs in the SOC to how much it can take on alongside human analysts. But every serious conversation with a CISO eventually lands on the same question: can I trust it?
Trust isn’t a model problem. It’s a grounding problem.
In Torq’s 2026 AI SOC Leadership Report, 90% of security leaders said explainable AI decisions matter most to an AI SOC platform. The number tracks a deeper concern. The real bottleneck in AI-driven response is whether the agents are reasoning on grounded truth. Model capability and execution speed have raced ahead; the grounding hasn’t kept up.
Most AI agents in the market re-query the same sources for every alert. Each time a case opens, the agent rebuilds the picture from scratch. When the case closes, the picture disappears. The next investigation starts at zero. Analysts end up spending 85% of time of their triage time on contextualization — manually assembling a story that, in any well-architected platform, should already exist before the agent ever shows up to the case.
Now, with the acquisition of Jit, Torq is even better equipped to uncover that story and act upon it.
Why Jit
Trust is the barrier to AI in the SOC, and agents have to be grounded in real, current truth to earn it. Torq is built to integrate across the full security stack and execute across the full threat lifecycle. Execution is the easy part once the foundation is right. The harder part is making sure every decision is grounded in what’s true about the environment at the moment the decision gets made.
Jit is an agentic security platform whose agents reason on top of a comprehensive Security Context Graph. The Jit team built a live graph layer that their agents consume in production to make grounded decisions, along with the patterns that feed those decisions back into the graph as agents operate.
Jit doesn’t just inventory what exists in your environment. It understands what your environment means. Who is who, what’s sensitive, what’s exposed, why an alert that’s medium severity for one user is critical severity for another, even when the two users are sitting on identical machines.
For Torq, this accelerates work already underway. We’ve been building context into agentic decisions from day one. Jit closes the gap between where we are and where the next phase of the AI SOC needs us to be — by years. With Jit on board, Torq becomes the first AI SOC platform that reasons from full context and acts on full context, with every action traceable back to the grounded decision that produced it.
What Is the Torq Context Graph?
The distinction between knowledge graphs and context graphs isn’t new. It’s been discussed in the graph database community for years. A knowledge graph captures entities and relationships: what exists and how it connects. Users connected to devices. Devices connected to networks. Useful, but incomplete. It tells you what is, not what it means.
A context graph layers operational meaning on top of that structure. When a fact was true. Where it came from. What policy governs it. Why a decision was made on top of it.
What’s new is applying that distinction rigorously to security operations and wiring it into agents that reason and act on top of it. That’s what Torq, and now Jit, have been building.
Take the canonical example. Craig and John work at the same company. Same laptop model. Same applications. The same alert fires on both endpoints. A knowledge graph sees two nearly identical situations. A context graph sees something else entirely: Craig is a contractor with read-only access to public marketing assets, while John is a finance director with privileged access to the M&A data room. Same alert, different stories, different verdicts, and different responses.
The Five Dimensions of a Context Graph
Five dimensions elevate a context graph from informational to agentic reasoning-grade context.
Temporal Context (When): Captures time-based validity (valid-from, valid-to), transaction dates, and sequence. The graph supports time-travel queries — what was true about this asset 14 days ago when the original alert first fired? — and reflects historical validity, not just the current state.
Provenance Context (Source): Tracks where every statement came from, how reliable the source is, and when the data was ingested. The graph knows which system or which person provided each piece of information.
Semantic Context (Meaning): Defines specialized relationships rather than generic links. The edge between two nodes isn’t a vague “related to.” It’s “approved by,” “transforms,” “governs,” or whatever the actual operational relationship is.
Governance Context (Constraints): Embeds policies, security access controls, and retention rules directly into the graph as queryable nodes and properties.
Decision Trace Context (Why): Every triage verdict, case decision, exception, and override is captured as a first-class node. Who made the call? What context did they have at the time? Which SOP did they follow, or choose not to follow, and why?
The fifth dimension is what makes the Context Graph different from anything else in the security graph space today. Decisions are modeled as nodes — with their context, their justification, and their outcomes — rather than buried in free-text fields nobody can query. That’s what lets agents detect patterns in how a SOC actually operates and adapt to the team’s real judgment, not the version written down two years ago in a runbook.
Capturing the Decisions, Not Just the Data
The hardest knowledge to capture in a SOC isn’t the data, it’s the judgment. Why did the lead analyst override the playbook last quarter? Why does this team always escalate an alert type that policy says to auto-close? Why did the on-call grant a temporary exception, and why did the team lead reverse it the next morning?
This knowledge lives in senior analysts’ heads, in Slack threads, and in the gap between what the SOP says and what the team actually does. When an analyst leaves, most of it walks out the door. Agents trying to support the team hit it as a wall: the documented process says one thing, the institutional reality is another, and they have no way to learn the difference.
The Torq Context Graph captures decision traces as native graph objects. Every override, every approved exception, every deviation from SOP, with the surrounding context of when and why. The longer you run Torq, the more the graph reflects your SOC’s actual operating logic, not the version written down two years ago.
A graph that goes stale produces decisions that do the same. The Torq Context Graph is built to keep up with the environment as it changes — close to real-time, where the data sources support it, on regular refresh cycles where they don’t. By the time the next alert fires, the agents’ reasoning on it have the current view of the environment to work from.
That’s what makes meaningful AI assistance possible. An agent that knows your SOPs is brittle. An agent that also knows when your senior analysts deviate from them, and why, is one your team can rely on alongside them.
Learning Your People, Process, and Technology
Every decision Torq AI Agents make feeds back into the Context Graph, enriching the next investigation or case. This is the difference between an AI SOC that simply processes alerts and one that genuinely learns and gets better at security over time.
People: The Context Graph learns how your team makes decisions. What analysts override, what they approve, and what exceptions they grant under what circumstances. Over time, the AI calibrates to your organizational judgment instead of a generic industry baseline.
Process: Every Torq AI Agent is context-aware from the moment it’s created. It already knows which assets are sensitive, which users have elevated privileges, and which integrations are available and trusted. As your processes evolve, the Context Graph evolves with them. Your team isn’t maintaining static contextual guidelines for every agent. Every Torq AI Agent draws from a single source of truth in real time.
Technology: As your security stack changes, the Context Graph updates. New integrations come in, old tools get deprecated, and the Torq AI SOC Platform adapts to your new environment. Workflows don’t break the day a key SME leaves the company, taking the institutional knowledge with them.
Customer-specific learning, with proper data isolation, produces a more precise and better-calibrated AI SOC. Your data stays in your environment, never touching a shared pipeline. With the Torq Context Graph, the longer you use Torq, the better it gets for your environment. Point solutions come and go. The platform underneath the SOC has to be the part that compounds.
End-to-End SecOps, Grounded in Full Context
SOC analysts need the full story to do their jobs well. Without it, you have a lot of information that doesn’t make sense in isolation. The Context Graph is what lets Torq tell the whole story behind every alert.
Torq is among the first companies in SecOps to build a real Context Graph. With Jit on board, Torq is the only company basing every agentic decision on the full story across the full lifecycle of the case — not just delivering an enriched alert with recommended next steps, but acting end-to-end from triage through response, with every agentic action traced back to the grounded decision that produced it.
The Context Graph is the new foundation underneath everything Torq customers already run. It makes the platform materially better across the board, without adding a separate product line for teams to adopt.
Build
Security engineers using the Agentic Builder create new workflows on top of a live, context-aware model of the environment. Builder gets smarter and faster because it works from the same grounded truth every other part of the platform draws on. Engineers stop repeating static instructions. They build on a live model.
Triage
Verdicts come from the full story of an alert, not a correlated signal enriched by threat intelligence. The Torq AI SOC Platform understands context, not just signals. Real risk surfaces because Torq knows what “real risk” means for your specific organization.
Investigate
Torq HyperAgents™ don’t re-query the SIEM, the EDR, and the IAM from scratch for every case. Investigations compound. Every agent reasons from the same shared, current, normalized intelligence layer. Planning, reasoning, and execution stay consistent across every case the SOC handles.
Respond
Socrates coordinates response actions grounded in the same context that produced the triage verdict. Every containment decision and remediation step traces back through the full reasoning chain, transparently documented at every step. Every action is auditable. Every decision can be replayed with the context that was true at the time. Nothing operates on a siloed data point.
The Future of Torq with Jit
Trust in AI-assisted security operations won’t come from better models. It will come from better grounding. From agents that can show, for any recommendation they make, exactly what they knew, when they knew it, and why they acted on it.
New models will only improve the reasoning of the agent and its general knowledge of the world or of cybersecurity. That won’t improve its capability to understand your environment, your tech stack, or your particular company policies. Only a comprehensive organizational context can do that.
The Torq Context Graph, now strengthened by Jit, is how we get there. Every alert investigated, every response executed, every exception granted feeds back in. The longer you run Torq, the more the platform reflects how your SOC thinks.
That’s the foundation the AI SOC has been missing, and it’s the foundation we’re now building on.
Leonid Belkind is a Co-Founder and Chief Technology Officer at Torq, the AI SOC platform. Prior to Torq, Leonid co-founded Luminate Security, a pioneer in Zero Trust Network Access and Secure Access Services Edge. At Luminate, Leonid guided this enterprise-grade service from inception, to Fortune 500 adoption to acquisition by Symantec.
David Melamed is the new Head of Emerging Technologies at Torq, joining through the company’s acquisition of Jit, which he co-founded and led as CTO since 2020. A cloud security veteran with more than 20 years of experience, David previously held senior technical roles in the Cloud Security CTO Office at Cisco (via the CloudLock acquisition) and at MyHeritage.
Someone implements Torq. They see what it does to their SOC. They start evangelizing it internally. And when their own career path eventually points somewhere new, they reach out.
This is the second time we’ve written this blog, and this time, four more former customers came to us: Austin Dix, Nate Thompson, Casey Howard, and Jeremy Herzog.
Different companies, different industries, and different team sizes. But the same arc: they hit a wall with their existing tools, found Torq, saw what was possible, and eventually decided they wanted to be part of building it.
Meet the Team That Left Manual Security Behind
Casey Howard, Sales Engineer
Casey has spent his career in security operations, automation, and AI-assisted workflows, building programs focused on what actually moves the needle: speed, clarity, and measurable outcomes. His take: most SOC teams aren’t short on talent or tools — they’re short on connected systems and time. After his team cut MTTR by 90% with Torq in the first month, he came here to make that the norm, not the exception.
Jeremy Herzog, Manager, Solutions Engineering Lab
Jeremy spent eight years at an MSSP, joining as an individual contributor engineer and rising to Director of Engineering — scaling their small enterprise segment from zero to 120 customers and leading implementation, detection engineering, and Tier 2/3 operations. After his team finally got automation off the ground with Torq (and solved problems that had been stuck for six years), he came here to build the environments that help the sales engineering team win deals.
Nate Thompson, Sales Engineer
Nate is a cybersecurity leader with 18+ years of experience transforming security operations at Dana Incorporated, a global Fortune 500 automotive supplier. A founding member of the cybersecurity program, Nate was one of the driving forces behind modernizing the company’s security stack — replacing legacy platforms, building automation and analytics capabilities, and championing the adoption of AI across security operations. As a Sales Engineer for Strategic Accounts at Torq, Nate helps security teams solve the same problems he spent his career living.
Austin Dix, Customer Success Engineer
Austin spent years running a lean SOC in the defense industrial space, where data misclassification carries real legal consequences. His team manually pulled CSVs and uploaded data classification reports to a DLP platform until he found Torq during a second evaluation round and saw what automation could actually do. As a Customer Success Engineer at Torq, Austin now helps lean teams skip the years he spent reinventing the wheel.
How It Started
Every story starts the same way: a security team doing its best with tools that weren’t built for what they actually needed.
Austin was running a five-person SOC in the defense industrial space. His SIEM vendor’s SOAR offering was poorly implemented, and his ticketing platform required an act of Congress to make any changes. The team was manually running data classification reports, pulling CSVs, cross-referencing project lists, and uploading them to a DLP platform. In an industry where misclassified data isn’t just a mistake — it’s a liability — that kind of manual work was untenable.
Nate’s team at an automotive manufacturer was automating with homegrown Python and PowerShell scripts. “While they worked, it was very limited,” he said. “We would have to maintain all of that ourselves.” The team was a skeleton crew — Nate, one or two others, and an engineer who knew Python. That was it.
Casey was managing an MSSP and a legacy case management ticketing module at a financial services company. Three integrations the team wanted, three additional line items. Edge-case integrations? Not possible at all. The team needed bi-directional sync between source systems and case management. Their tooling couldn’t deliver it.
Jeremy was Director of Engineering at an MSSP. His SOC team had tried and failed to implement a SOAR that got rebranded and folded into a larger platform before it even started. “They had it for a year and never really got it off the ground.” The result: an MSSP with limited automation or response capabilities — a distinct disadvantage for winning new business and retaining existing clients.
The Breaking Point
Austin’s breaking point wasn’t technical. It was a vendor who refused to give him a demo. His team had run a formal bake-off, picked a winner, completed a POC, and gotten approval. Then Austin tried to bring in his infrastructure team to buy additional licenses. The vendor said, “No demo until you sign a purchase order.” Austin said, “All right, I’m going to go find somebody else that will.”
Nate’s company got XSOAR added on for free during a renewal cycle, which killed the evaluation they were already running. It helped at first, but they hit a wall fast. “All we really did was give our scripts a pretty interface. We could draw boxes, but if we wanted to do something that wasn’t a box, we had to engage professional services. That took weeks and months.” With a two-person team and a growing backlog, everything froze.
Casey evaluated every major SOAR and automation on the market. Two were eliminated solely due to licensing models — user-based pricing with an MSSP was prohibitive. Another charge per execution run. It came down to Torq and one other vendor.
Jeremy’s SOC team couldn’t get their SOAR working, so leadership handed the project to his engineering group. He evaluated three options. Torq floated to the top.
The Switch to Torq
Austin got introduced to Torq on his second evaluation round, and it was “night and day.” The team automated data classification for their DLP platform and used Torq as a consolidation layer for alerts from across endpoint tools, the SIEM, and identity systems. “This was before case management, so we basically used Torq to recreate case management. It brought everything together for us.”
Nate will never forget opening the Torq interface for the first time. “It was very intuitive. It just clicked.” He converted most of his legacy workflows during the POC alone. “I fell in love with the platform.” When the competing vendor came in for the bake-off, the contrast was immediate: “I sat there and was like, I don’t know which box I’m supposed to drag over. And when you finally drag one over, there are like 12 configuration steps inside.” If he couldn’t figure it out — and this was 80% of his job — his SOC analysts never would.
“I’ll never forget getting into the Torq interface for the first time. It was very intuitive. It just clicked.” – Nate
Casey’s team chose Torq because it was a security-focused platform built for security operations teams. The feature that delivered the most impact was the AI-generated case summary — pulling everything into one view so analysts could quickly triage and decide: true positive, escalate, or close.
“AI was an afterthought back then, but once we saw the AI capabilities in Torq, it became where most of our value actually came from.” – Casey
Jeremy made a bet with his VP of Operations: “I’m putting my credibility on the line — if you buy this product, we will have this implemented in under 30 days.” They signed. They were operational in two weeks. “After that, I just started using Torq to solve all of the problems I’d had for years. Problems I’d been dealing with for six years — Torq let me build workflows to solve in a matter of weeks.”
Favorite Torq Features
Ask any of them what stood out, and it comes back to speed, simplicity, and the ability to make non-engineers productive.
At Austin’s organization, the Torq platform was so accessible that interns were able to build. “We even had interns building automations in the platform, because the no-code interface was that simple.” Nate could go from a use case — a sentence or two — to a production-ready workflow in less than 24 hours. Other teams saw what the SOC was doing and wanted in. He extended Torq into GRC, built just-in-time USB access workflows, and started automating firewall changes for IT operations.
Casey loved the universal connectivity — API calls, webhooks, SSH, AWS, email ingestion. “Being able to connect with everything in any way we wanted to was amazing.”
After a month on Torq, the team reduced MTTR by about 90%.
Jeremy knocked out years-old problems with project management style and democratized access so more engineers could build. “It just took off from there.” By the time he left, Torq was ingrained in all four of the MSSP’s managed services.
“I democratized it, got more engineers building in the Torq platform. It just took off from there. We saved everybody time. We made everybody’s lives easier.” – Jeremy
The Move to Torq
Austin had already left his SOC role and joined a different organization when the Torq team called. He’d told them years earlier: if you ever need anybody, let me know. They took him up on it.
Nate became a Torq evangelist before he became an employee — talking up the platform at events and demoing to other teams. “I wanted it to be for a product I was truly invested in. There are only a handful of those in my career.”
Casey saw the business outcomes from Torq and felt like everyone deserved access. “Being a security analyst and having to do alert triage — it’s mind-numbing. If I can help anyone else not have to do that low-value work, that’s what I wanted to do.”
Jeremy’s motivation started with the people. “This team is hands down the best customer relations team I’ve ever worked with in my career.” But it was also the product. “It was my first foray into automation, and it’s kind of become my native language.”
What They Didn’t Know as Customers
Every one of them says the same thing from the inside: the platform is even further along than they knew as customers.
Nate expected deterministic automation. What he found was that AI capabilities had leaped forward. “To have that as a native part of the platform — I was surprised with how quickly the R&D and product team were able to move forward.”
Casey didn’t have AI Agents as a customer and was trying to build his own agent workflows through an LLM API. “It was janky, it was so hard to work with. I’ve built so many agents now that I wanted to build when I was a customer, because it’s so easy to do it now.”
Jeremy says case management was the revelation — far more robust than he expected. And Austin wishes he’d leaned on the Torq community more. “We did a lot of reinventing the wheel that I wish we hadn’t.”
“Torq is going to make a night and day difference for any security operations team within weeks, if not days.” – Austin
As for what’s next, they all land on the same two things: Auto Triage and the Agentic Builder.
Austin: “If I was back buying Torq again and Auto Triage was a thing, I would buy it 100 times over.” Nate sees the Agentic Builder collapsing time-to-value: “What I could do in 24 hours, you could almost do in a single meeting.” Casey sees Torq pulling away from the pack: “There are a bunch of AI SOCs now, but they only do alert triage. We can do the full incident lifecycle.” And Jeremy sees the Agentic Builder as the convergence of everything he loves: “The fact that we’re extending that into building workflows is amazing.”
We’re moving fast, and the team is growing. If you want in — we’re hiring.
92% of security leaders say something is actively reducing their trust in AI within the SOC. These aren’t skeptics, they’re people who have already adopted AI and believe in its ability to enhance security operations. We know from the 2026 AI SOC Leadership Report that AI is already widely adopted in the SOC, with 94% of organizations using it in some capacity.
And yet, there’s still an AI security and trust gap in the SOC. Why?
Confidence Isn’t the Issue. Deployment Is.
Digging into the data from Torq’s AI SOC Leadership Report, one gap stood out as the most shocking. Across every SOC use case we measured, confidence in AI’s ability to get the job done is nearly universal, ranging from 91% to 97%. CISOs and security leaders aren’t sitting around debating whether AI can handle the work; they know it can. But actual adoption tells a different story.
Vulnerability management and threat hunting lead AI adoption metrics at 56% each. Followed by case management, reducing false positives, investigation, and remediation. What was surprising is that triage is the least deployed AI use case, with only 37% adoption — even though triage is arguably the most obvious fit for AI. SOC teams are overwhelmed with massive amounts of false-positive–riddled alerts, making triage one of the most repetitive and time-consuming tasks analysts face.
If the use case best suited for AI in the SOC is the one organizations have been slowest to adopt, what does that say?
When we dove deeper into each use case, the responses helped pinpoint exactly what challenges SOC teams were experiencing that led to the adoption vs. confidence gap. The top response for triage was the need for too much human review (34%); for investigation, manual enrichment (32%) and unreliable conclusions (31%) were neck and neck; and for response, the most common answer was lack of trust (33%).
It’s not a capability problem. It’s a lack of trust in the products themselves.
What’s Actually Reducing Trust in AI?
When we asked 450 CISOs and security leaders this question, the answers weren’t what you might expect (or maybe they were, given how universal they were). Nobody led with “I’m worried that AI will take my analysts’ jobs” or “I’m not comfortable with the idea of autonomous remediation”. These are the answers other vendors are telling you to have, but the reality is, the top concerns were far more fundamental than that, and included:
Data privacy concerns: 45%
False negatives (missed threats): 40%
Data governance: 37%
Black-box AI: 32%
Looking at these four top concerns together paints a pretty clear picture. Security leaders aren’t questioning whether or not AI works; they’re asking:
What data is AI accessing?
What is AI doing with that data?
Why is AI making the decisions it’s making?
When we break down the responses by seniority level, the story remains the same. The top concerns surrounding AI in the SOC were:
Executives: False negatives
VPs: Data privacy
Directors: Black-box AI
Senior Managers: Loss of control
These responses aren’t contradictory;they’re all expressions of the same need: visibility and control at every level.
What Would Build Confidence in AI in the SOC?
We asked what was reducing trust in AI, so it only made sense to ask what would build that confidence too and the answers were just as telling.
Security teams aren’t looking for less AI; they are looking for more visibility into the AI they already have. They want to understand the planning and reasoning that goes into agentic execution. They want to be able to report to their executives that the AI solutions they’ve invested in are protecting their data and meeting their organization’s unique regulatory and compliance requirements.
And most importantly, they want to maintain the flexibility of human-in-the-loop control. Not human intervention at every step, but the ability to control and customize where and when human analysts should step in, either as overseer or final decision maker. High-severity incident with a critical system on the line? Humans make the call. Low-severity, high-confidence attack pattern? AI handles end-to-end.
Rearchitecting AI for Security and Trust
90% of security leaders say that explainable AI decisions are critical to a true AI SOC platform. The current gap between confidence and deployment exists because too many AI SOC solutions can’t provide the type of transparency that builds trust. As a result, SOC teams are spending their time double-checking AI decisions, doubling the work, and not realizing the time savings that AI in the SOC was intended for.
A true AI SOC platform needs to inherently answer the simple questions that SOC teams are asking — what tools is the AI accessing, what data is the AI looking at, and why did the AI reach the conclusion it did? Until those questions have clear, verifiable answers built into the platform architecture, the ceiling on AI expansion in the SOC isn’t the technology. It’s trust.
What Transparent AI Looks Like
The Torq AI SOC Platform was built with these concerns in mind. We understand the importance of transparency in building trust in human-AI collaboration. Here’s how the Torq AI SOC Platform addresses each one directly.
Declarative instruction: Torq HyperAgents™ work under your explicit direction. You give each agent a role, an objective, behavioral guidelines, and specific instructions. You define the tools that they can use (as broadly as a workflow or as granularly as a single step), the data they can access, and the decisions they are authorized to make. Control is built in from the start, not bolted on as an afterthought.
AI reasoning and output visibility: Every agentic action is documented in a transparent timeline view that maps the reasoning leading to each execution. Analysts aren’t left guessing why a verdict was reached, or what evidence supports a specific conclusion. The planning, reasoning, and execution are reviewable and structured for human validation — in real time — with manual override always available.
Immutable audit logs: Every AI decision, action, and reasoning chain is recorded and uneditable. Not just for compliance purposes, but because auditability is what builds trust in AI across the organization. When a CISO asks “What did the AI do, and why?”, the answer is already written, traceable, and defendable.
Human-AI collaboration: Torq Socrates coordinates the full platform, with humans on the loop by design. Response actions can execute completely autonomously for high-volume, high-confidence scenarios or with human-in-the-loop confirmation when severity or business context demands it. Analysts set the boundaries and build in off-ramps for human intervention, while Socrates documents and learns over time. As confidence in AI grows, SOC teams can grant greater autonomy across day-to-day use cases. Trust is earned, after all.
The Confidence SOC Teams Need
The #1 confidence booster in A isn’t more features or better algorithms — it’s transparency. Show how AI reached its decisions, and teams will trust it more. Give them the ability to dial autonomy based on context, and they’ll grant more of it. AI security and trust come down to architecture, not marketing. A true AI SOC platform is built for trust from the inside out.
For more on how the Torq AI SOC Platform is the only enterprise-ready AI SOC that security leaders can actually trust, check out the complete blog series below.
John White is the Field CISO for EMEA at Torq. A respected security executive with more than 20 years of leadership experience, John previously served as CISO at Virgin Atlantic, where he led a multi-year transformation deploying the Torq AI SOC Platform to modernize cyber operations. Prior to that, he built and transformed security functions for global organizations, including ASOS, Liberty Global, AEG Europe, and KPMG.
Many security functions today still rely heavily on humans for detection, triage, and response, often by design. But as environments grow more complex and alert volumes explode, it raises a hard question: Can this approach scale on its own?
Adopting AI in security operations isn’t just about adding tools. It means rethinking the SOC operating model itself — roles, workflows, and team structures. Here’s why, and how.
Human Speed Is Not Enough
AI-powered attackers are rewriting malware in hours, not weeks. They don’t sleep, don’t take holidays, and don’t slow down between shifts. The uncomfortable truth for every security leader: a defense built around human reaction times is already structurally defeated.
Earlier this year, Check Point documented a threat actor who used AI to build an entire malware platform. What had previously required a 30-week development cycle was executed in hours. Let that land for a moment. A months-long engineering effort, compressed to a morning. And the defenders on the other side? Still triaging alerts by hand. Still waiting for a human analyst to open the ticket.
I’ve spent more than 20 years in this industry. I’ve led security transformations at Virgin Atlantic, ASOS, Liberty Global, and others. I’ve seen every generation of the threat landscape evolve — from script kiddies to organized crime to nation-state actors. But I have never seen a shift as fundamental as this one. The emergence of agentic AI on the offensive side has broken the basic assumption that human defenders, given enough tools and talent, can keep pace. They cannot. Not anymore.
94% of organizations are using AI in the SOC in some capacity
80% are still running fragmented tools
The average SOC runs 7 different AI tools — most of them disconnected
Security teams have always faced a staffing problem. The talent shortage is not new. But something changed recently: the gap between the attack surface and the available defense capability stopped being a hiring problem and became a physics problem. You cannot hire your way to machine speed. You cannot add a third shift to match an adversary that operates continuously, at scale, without fatigue or error.
Consider what a machine-speed attack looks like in practice. An AI-assisted attacker is not simply running faster phishing campaigns. It is dynamically adapting malware signatures to evade detection. It is scanning and correlating exposed credentials across the internet in real time. It is probing your attack surface while your analysts are writing up last night’s incident report. The asymmetry is not modest. It is categorical.
“You cannot fight machine-speed threats with human-speed defense. A security organization built around 9-to-5 shifts and human triage cycles is, structurally, indefensible against what’s coming.”
– John White, Field CISO, Torq
Why “More Tools” Is the Wrong Answer
The instinctive response to a growing threat landscape has always been procurement. Add a new detection layer. Buy the next-generation endpoint solution. Subscribe to another threat intelligence feed. The average SOC today runs seven AI-powered tools. 10% are managing 10 or more. Across the enterprise, organizations deploy an average of 83 security tools from 29 different vendors.
And yet analysts are more overwhelmed than ever. Not because the tools don’t work in isolation, but because a human being sits at every integration point — manually bridging context between platforms, fighting alert fatigue, and making triage decisions that should have been automated years ago. More tools without a unified execution layer don’t multiply capability. It multiplies noise.
85% of security leaders say they want consolidation over fragmented point solutions. Yet 80% are still running exactly that. The intention exists. The SOC operating model to support it does not, because those models were designed for a slower, more forgiving threat environment.
The analysts on your team are not unhappy because they dislike security. They’re unhappy because they’re not doing security work. They’re drowning in noise instead of solving problems. I’ve seen this firsthand. When AI handles triage at scale, something remarkable happens: you look out at your team, and they don’t seem overwhelmed anymore. They have time to think. They apply quality, not just throughput. The work they were hired to do becomes possible again.
Accountability Has Changed
Here is the harder conversation I have been having with CISOs across EMEA: the accountability framing has fundamentally shifted.
A decade ago, a CISO’s culpability was largely reactive — did you have reasonable controls in place at the time of breach? That question has not gone away. But a new question has emerged alongside it: Did you fail to adopt capabilities that would have materially reduced your exposure?
Failing to govern and deploy AI-driven security is no longer a conservative choice that preserves safety. It is a strategic decision to remain structurally behind. And boards, insurers, and regulators are beginning to understand the difference. CISOs who treat 2026 as a transition year — a year to watch and learn — will find that window has already closed around them.
I want to be clear: this is not an argument for removing humans from the loop. Quite the opposite. The decisions that require genuine human authority are the ones that demand business context — your organization’s risk appetite, the political environment you’re operating in, and the board’s strategic direction. That judgment layer cannot and should not be automated.
But the execution layer — the triage, the enrichment, the initial containment, the correlation of signals across your stack — that needs to run at machine speed. And it can.
What the New SOC Operating Model Looks Like
When I evaluate security platforms now, I use a simple filter: does this require constant human intervention to function? If yes, it becomes a bottleneck, not a defense. Any tool that cannot operate autonomously within clearly defined constraints, while still providing real-time observability, will not scale against the threat environment we are describing.
They reduce cognitive load. They interpret volumes of data and surface the insights that matter, rather than adding to the noise.
They move beyond detection into recommendation and, where appropriate, remediation.
They are continuously self-measuring, turning security from a reactive function into an optimizing system that can demonstrate its own effectiveness.
This is the SOC operating model I spent years trying to build from the inside at Virgin Atlantic, and the reason I moved to Torq. The agentic SOC — where machines fight machines, where AI Agents handle the execution layer at the speed the threat requires, and where human analysts focus on the judgment calls that actually need them — is not a vision document. It is deployable today.
The question for every security leader reading this is not whether this future is coming. It is whether you will be leading it or responding to it.
Here’s what happens when the SOC operating model is redesigned around the execution layer running at machine speed:
8.2x faster incident detection-to-containment
75% reduction in MTTR for common security incidents
95% decrease in manual tasks for Tier 1 SOC analysts
100% of Tier 1 tickets auto-remediated without human involvement
4x capability to handle security alerts with the same-sized team
80% alert fatigue reduction
“AI isn’t a tool you bolt onto your existing SOC. It’s forcing us to fundamentally rethink how security organizations are structured, staffed, and measured. The CISOs who redesign their SOC operating model now will build teams that operate at machine speed.”
– John White, Field CISO, Torq
A Call to Action: Redesign Your SOC Operating Model
Start with your current state, but do not think in disciplines. Think in outcomes. Where does human latency create an unacceptable gap? Where are your analysts spending time on decisions that should be automated? Where is the absence of 24/7/365 coverage leaving you exposed in the hours between shifts?
Design the SOC operating model of the future with AI and automation at its heart — not layered on top of a legacy model, but embedded from the foundation. That means 24/7 coverage that never sleeps, consistent execution that never fatigues, and human judgment applied exactly where it adds irreplaceable value.
The threat is already operating at machine speed. The only rational response is to meet it there.
Track what matters. MTTI, MTTR, autonomous case closure rate, analyst hours reclaimed, false positive suppression, and escalation accuracy. Not vanity metrics like “alerts processed.”
Baseline before you deploy. Without pre-deployment benchmarks, any improvement is anecdotal and indefensible at budget time.
Benchmark against real results. Carvana automated 100% of Tier-1 alerts. HWG Sababa improved MTTI and MTTR by 95%. Valvoline saved 6 to 7 analyst hours per day within 48 hours.
Report in board language. Translate AI SOC metrics into risk reduction, increased capacity, improved coverage, and greater trust maturity.
Every security vendor shipping an AI product in 2026 makes the same promises. Faster triage. Shorter response times. Fewer false positives. Reclaimed analyst hours. But, six months after deployment, most security leaders still cannot answer a straightforward question from the board: Is this thing actually working?
The problem is not necessarily that AI in the SOC fails to deliver (although in many cases, when the AI is immature or bolted-on, it does). The core problem is that most organizations never defined what “working” looks like before they deployed it. They skipped baselines, tracked the wrong metric, or failed to build a reporting framework that connects SOC performance to business outcomes. So when the CFO asks what the organization got for its AI investment, the CISO is left pointing at vendor dashboards full of numbers that mean nothing to anyone outside the SOC.
That is the accountability gap. It is the difference between an AI deployment that earns expanded investment and one that gets quietly deprioritized at the next budget cycle.
This article provides the AI SOC metrics framework to close that gap: the metrics that indicate whether AI is delivering real value, the baselines you should have captured before deployment (and how to reconstruct them if you did not), the benchmarks from real production environments that show what “good” looks like, and the reporting model that translates AI SOC metrics into the language your board already speaks.
What AI SOC Metrics Actually Matter?
Not every number your SOC produces tells you whether AI is delivering value. The right AI SOC metrics are genuinely diagnostic.
The AI SOC metrics that matter:
Mean Time to Investigate (MTTI) measures whether AI is accelerating the part of the workflow where analysts spend most of their time. Faster triage speed has become table stakes for AI SOC tools. The real test is investigation speed — whether the AI is doing meaningful work like enriching data, correlating events, and building timelines, instead of just routing alerts to the same queue slightly faster.
Mean Time to Respond (MTTR) is the end-to-end metric: from alert to resolution. This is the number boards understand because it maps directly to risk exposure. Every minute between detection and response is a minute an attacker has to move laterally, exfiltrate data, or escalate privileges. When AI compresses MTTR, it compresses the window of exposure.
Autonomous case closure rate tracks the percentage of cases that resolve without human intervention and the accuracy of that resolution. This is the metric that separates agentic AI from assisted tooling. If a human still has to review every case the AI touches, you haven’t automated anything.
Analyst hours reclaimed measures the time your team got back for higher-value work. Not “alerts processed” but actual hours. The distinction matters because it connects directly to capacity, which in turn connects to what your team can now do that it couldn’t before: deeper investigations, threat hunting, proactive risk reduction, and new automation development.
False-positive suppression rate indicates whether the AI is genuinely filtering noise or merely relabeling it. If your analysts are still manually reviewing the same volume of cases under a different status label, false-positive suppression isn’t working.
Escalation accuracy measures whether the AI makes the right call when it does hand a case to a human. High autonomous closure rates mean nothing if the cases that are escalated are wrong, incomplete, or lack context. Escalation accuracy is a direct proxy for analyst trust.
The metrics that mislead:
“Alerts processed” counts volume without outcomes. Processing 10,000 alerts means nothing if 9,500 of them didn’t need investigation.
“Time saved per alert” ignores whether the alert warranted investigation. Saving 30 seconds on a false positive isn’t time savings.
“AI accuracy” without context hides the failures that matter most. Consider this scenario: 99% accuracy on easy cases and 60% on hard ones isn’t 99% accuracy. It’s a weighted average that misleads the buyer.
Baselining Your AI SOC Metrics Before Deployment
This is the step that’s all too easy to skip, but without it, you can’t prove improvement later. Before deploying AI in your SOC, capture current-state baselines for MTTI by case type (phishing, malware, identity compromise, etc.), MTTR by severity level, analyst hours spent on Tier 1 triage, investigation, and strategic work, case backlog depth and aging, and escalation volume and accuracy.
Without these baselines, any post-deployment improvement is anecdotal. Your MTTR dropped? Compared to what — last month, which happened to be a quiet threat period? You’re closing more cases autonomously? Were you tracking closure rates before, or just estimating?
With baselines, you have a before-and-after story that boards understand. Not “we think things are better” but “our MTTI for phishing cases dropped from 45 minutes to six minutes, and here’s the data.”
If you’ve already deployed AI without capturing baselines, you’re not out of options. Pull historical data from your SIEM and ticketing system for the 90 days prior to deployment. Reconstruct approximate MTTI and MTTR by case type using ticket timestamps. Survey your analysts on how they spent their time pre-deployment — their estimates won’t be precise, but they’ll give you a good comparison point..
AI SOC Metrics Benchmarks: What “Good” Looks Like in Real Deployments
This is where the conversation shifts from theory to evidence. Most vendors publishing AI SOC content can tell you what metrics to track, but very few can tell you what the numbers should actually look like because they don’t have customer data to back it up.
Here’s what production deployments have demonstrated.
MTTR trajectory: HWG Sababa, a managed security services provider, achieved a 95% improvement in MTTI and MTTR for medium- and low-priority cases, and 85% for high-priority cases — with investigation and response now occurring nearly simultaneously in under eight minutes. That’s a measurable, repeatable benchmark across priority tiers. If your AI has been live for six months and your MTTR curve is flat, the platform isn’t learning.
Autonomous closure rates.Carvana automated 100% of Tier 1 alert handling and 41 different runbooks within one month of deployment. Bloomreach‘s SOC uses Torq’s AI SOC Orchestrator, Socrates, to handle Tier 1 and Tier 2 tasks autonomously, freeing analysts from entirely repetitive triage. These results establish the benchmark: leading organizations are closing the majority of Tier 1 and even Tier 2 cases autonomously within months of deployment. If your autonomous closure rate has stalled after six months, review your confidence thresholds, workflow design, and the scope of cases you’re allowing the AI to handle.
Analyst hours reclaimed.Valvoline saved 6-7 analyst hours per day after deploying Torq — and saw measurable ROI within 48 hours of go-live. That’s not a percentage on a dashboard. That’s time analysts can point to on their calendars — hours redirected from repetitive triage to investigation, threat hunting, and automation development.
SOC throughput without headcount growth.HWG Sababa nearly doubled SOC throughput with no new hires. Agoda compressed incident report generation from seven hours to 40 minutes. These results matter because they answer the question every CISO faces: Can I scale my SOC without scaling my team? The data says yes — if the AI is measured and managed correctly.
Use these benchmarks not as targets to hit on day one, but as reference points for your own deployment curve.
Turning AI SOC Metrics into a Board-Ready Reporting Framework
CISOs who successfully justify AI investment don’t present raw AI SOC metrics to the board. They translate those metrics into the four things boards care about: risk, cost, capacity, and trajectory.
1. MTTR reduction → Risk exposure reduction. Frame it as: “Our mean time to respond dropped from four hours to 12 minutes. That means an attacker’s window to operate inside our environment shrank by 95%.” Boards understand windows of exposure; they might not understand MTTR.
2. Analyst hours saved → Capacity gained. Don’t frame this as headcount reduction; frame it as coverage expansion. Instead: “We recovered the equivalent of 1.5 full-time analysts in capacity. That capacity is now allocated to threat hunting and proactive risk reduction work that we couldn’t staff before.” Boards understand that doing more with the same team is possible.
3. Autonomous closure rates → Coverage improvement. Frame it as: “Before AI, we could meaningfully investigate approximately 60% of incoming alerts. We now investigate 100%. Every alert gets full triage and, when warranted, a complete investigation — without adding headcount.” Boards understand coverage gaps. Telling them you closed the gap is more powerful than any MTTR chart.
4. Escalation accuracy → Trust maturity. This is the trend line that matters most for long-term buy-in: “In month one, the AI escalated cases at 82% accuracy. By month six, it was 96%. The system is measurably getting better at knowing when to act and when to ask for help.” Boards understand learning curves — show them one.
For reporting cadence, deliver monthly operational AI SOC metrics to SOC leadership — MTTI, MTTR, closure rates, escalation accuracy, and analyst utilization. These are your tuning instruments. Quarterly, deliver business impact summaries to the CISO and board — risk reduction, capacity gained, coverage improvement, cost avoidance, and the trend curves that show compounding returns.
How Long Does It Take for AI to Show Measurable Results in a SOC?
Tracking AI SOC metrics isn’t a one-time exercise. It’s a maturity journey, and the metrics should reflect that.
Month 1–3: Validate performance in shadow mode. Run AI decisions in parallel with analysts. Compare what the AI would have done against what analysts actually did. Establish accuracy baselines and identify where the AI agrees with your team and where it diverges. This phase builds internal confidence. If the AI matches analyst decisions a majority of the time on Tier 1 cases, you have the evidence to increase autonomy.
Month 3–6: Increase autonomy. Expand autonomous closure. Track escalation accuracy weekly. Tune confidence thresholds based on real outcomes, not theoretical risk models.
Month 6–12: Expand use cases. Benchmark against industry data. Extend AI into Tier 2 investigation, cross-team workflows, and compliance reporting. Demonstrate compounding improvement — not just in speed, but in scope.
Month 12+: Activate AI-driven insights. The AI surfaces trends humans couldn’t detect at scale — detection rule gaps, recurring misconfiguration patterns, team capacity forecasting, and emerging attack vector correlation. At this stage, the AI isn’t just executing your security strategy; it’s informing it.
The key signal to watch across all stages: AI SOC metrics should compound before they plateau. An early flat line means the platform isn’t learning. A late plateau after months of sustained improvement is what a mature deployment looks like. MTTR should keep dropping. Autonomous closure rates should keep climbing. Escalation accuracy should keep tightening. If your numbers plateau after month three, something is wrong. Either the AI isn’t learning from new data, the use cases aren’t expanding, or the confidence thresholds need adjustment.
The AI SOC Metrics Imperative
The organizations getting the most from their AI investment aren’t running the most sophisticated models. They’re running the clearest measurement frameworks — and they have the discipline to track them.
Define your baselines. Track the metrics that connect to outcomes. Build the dashboard your board actually wants to see. And benchmark against organizations that have already proven what’s possible.
What are the most important AI SOC metrics to track?
The AI SOC metrics that matter most are MTTI, MTTR, autonomous case closure rate, analyst hours reclaimed, false positive suppression rate, and escalation accuracy. Baseline these metrics before deployment and track them monthly. Organizations using Torq have demonstrated MTTI/MTTR improvements of 95%, autonomous alert management of 55%+ of total volume, and full Tier 1 automation within months of deployment.
What is a good autonomous case closure rate for an AI SOC?
Leading organizations achieve 55–100% autonomous case closure rates for Tier 1 and Tier-2 cases. HWG Sababa automatically manages approximately 55% of total monthly alert volume end-to-end. Carvana automated 100% of Tier 1 alert handling and 41 runbooks within one month. If your AI has been live for six months and autonomous closure is stagnant, review your confidence thresholds and workflow design.
How do you report AI SOC metrics to the board?
Translate AI SOC metrics into business language: MTTR reduction maps to reduced risk exposure, analyst hours saved maps to capacity gained (not headcount cut), autonomous closure rates map to coverage improvement, and escalation accuracy maps to trust maturity. Report operational metrics monthly to SOC leadership and quarterly business impact summaries to the CISO and board.
How long does it take for AI to show measurable results in a SOC?
Most organizations see initial results within weeks. Valvoline saw ROI within 48 hours of deploying Torq. However, the compounding value of agentic AI — improving accuracy, expanding use cases, surfacing operational trends — builds over 3-12 months. HWG Sababa achieved a 95% MTTI/MTTR improvement and nearly doubled SOC throughput without adding headcount, with the steepest gains occurring in the early months of deployment.