Contents
Get a Personalized Demo
See how Torq harnesses AI in your SOC to detect, prioritize, and respond to threats faster.
Most SOCs standardized on SIEM and SOAR — yet the promise of end-to-end automation never materialized. SIEM gave SOC teams centralized log visibility and correlation. SOAR promised relief from repetitive tasks through orchestration. But as threats scaled in speed and complexity, and security teams faced mounting pressure with fewer resources, these tools started to show their limits.
According to Francis Odum’s AI SOC Market Landscape 2025 survey of 300+ CISOs, organizations now face an average of 960 daily security alerts, and over 3,000 daily alerts at enterprises with 20,000+ employees. The report describes a “tsunami of data” crippling SOCs, compounded by slow triage and limited response capabilities in legacy tools like SIEM and SOAR.
Hyperautomation is a fundamentally new approach built for the modern SOC. It doesn’t just connect tools or run playbooks. It combines real-time integrations, no-code workflow design, and agentic AI to create a fully autonomous, adaptable system for detection, response, and remediation.
The Evolving Landscape of SOC Tools
To understand why Security Hyperautomation is redefining modern SecOps, it helps to look at how we got here.
- SIEM was built to tame the flood of security data, ingesting logs, correlating events, and supporting compliance mandates. It gave teams visibility but little action.
- SOAR followed, aiming to reduce manual effort by automating response through structured playbooks and tool integrations. It promised efficiency but delivered rigidity.
- Security Hyperautomation emerged when both began to crack under modern pressures, soaring alert volumes, hybrid cloud sprawl, analyst burnout, and the demand for real-time, intelligent response.
Legacy tools helped establish the foundation. But they weren’t designed for today’s threat landscape’s speed, scale, or complexity. That’s where Hyperautomation changes everything: bridging gaps, replacing brittle workflows, and enabling fully autonomous, AI-driven security operations.
Next, we’ll break down what each SOC tool delivers — and where they fall short.
SIEM: Built for Logging and Search, Not Speed
A SIEM (Security Information and Event Management) system collects, aggregates, and analyzes log data from across an organization’s IT environment. It centralizes visibility into security events, correlates data to detect potential threats, and supports compliance reporting.
SIEM platforms were built to give SecOps teams visibility. They ingest, normalize, and analyze data from firewalls, endpoints, servers, cloud apps, and more, centralizing logs into one place so teams can detect anomalies and satisfy compliance mandates.
SIEMs deliver:
- Centralized log aggregation and historical data analysis
- Rule- and pattern-based correlation for threat detection
- Dashboards and reports for frameworks like PCI-DSS, HIPAA, and ISO 27001
For a time, this was enough. But, the threat landscape and the SOC have changed. Modern environments are real-time, distributed, and hybrid. Threat actors exploit vulnerabilities in hours, not weeks. Meanwhile, SIEM solutions are built around static detection logic, batch processing, and reactive triage. They’re not designed to orchestrate response or handle fast-moving, multi-vector threats.
And they come with challenges:
- Configuration complexity: Fine-tuning SIEM systems requires deep expertise to avoid false positives and missed threats during setup.
- Integration hurdles: SIEMs often struggle to seamlessly connect with diverse security tools, limiting visibility and operational efficiency.
- Resource constraints: Deploying and managing SIEMs demands significant time, budget, and skilled personnel, often out of reach for lean teams.
- Hidden costs: Data ingestion and storage can balloon unexpectedly as log volumes grow, straining budgets and infrastructure.
- Data onboarding challenges: Normalizing and standardizing log data from disparate systems adds overhead and impacts detection accuracy.
- Scalability limitations: As environments grow, many SIEMs can’t keep pace with increased data volume, causing performance bottlenecks.
- Retention and compliance pressures: Meeting regulatory data retention requirements while controlling storage costs is a constant balancing act.
As a result, SIEM solutions often devolve into expensive search engines. They surface problems, but can’t solve them. Analysts still have to swivel-chair between tools, copy/paste IOCs, open tickets, and manually kick off an investigation or remediation. In a world that demands instant response, SIEMs stall at detection.
SOAR: Designed to Orchestrate, but Not Adapt
SOAR (Security Orchestration, Automation, and Response) platforms were designed to help security teams streamline incident response workflows. They integrate across tools like SIEMs, EDRs, and ITSM systems to orchestrate tasks and enforce processes through playbooks.
SOAR platforms were introduced to close the gap between detection and action. They aimed to reduce repetitive work by connecting disparate tools and codifying workflows. With SOAR, SOCs could automate ticket creation, enrich alerts, or trigger containment through predefined playbooks.
SOAR brought value through:
- Playbook-driven automation for common incident types (e.g., phishing, malware)
- API-based integrations between SIEM, EDR, firewalls, and ITSM platforms
- Structured response processes to reduce manual tasks and improve SLAs
However, SOAR platforms often introduce more challenges than they solve, including:
- Strategic misalignment: SOAR tools often fail to support broader security maturity or align with long-term operational goals.
- Cultural fragmentation: SOAR can reinforce IT silos by overlooking the human workflows and collaboration needed across teams.
- Resource diversion: SOAR often pulls skilled analysts away from high-value tasks to maintain, tune, and troubleshoot playbooks.
- Overhyped expectations: Many SecOps teams assume SOAR delivers full autonomy, only to face brittle workflows and limited intelligence.
- Integration burdens: Connecting SOAR platforms with diverse tools frequently requires custom code and ongoing maintenance.
- Vague success metrics: Measuring SOAR effectiveness is difficult without clear KPIs for response speed, coverage, or workflow impact.
- Code-heavy and complex: Most SOAR platforms require Python or custom scripting for core functionality.
- Fragile integrations: Workflows break easily when APIs shift or tools are updated, creating constant maintenance cycles.
- Slow to iterate: Even small changes demand developer time, testing, and deployment, delaying improvements.
This means SOAR becomes a bottleneck instead of an accelerator. Analysts depend on engineers to build or fix automations. Workflows lag behind emerging threats. Rigid architectures can’t adapt to dynamic inputs or decision branches — if something unexpected happens, SOAR stops.
And perhaps most importantly, SOAR lacks contextual intelligence. It can automate known paths but can’t think, reason, or react to the unexpected. This lack of adaptability is a dealbreaker for hybrid and cloud-native SOCs facing high alert volume and constantly shifting attack surfaces. That’s why we believe SOAR is dead.

Hyperautomation: A New Model for a New Threat Landscape
Security Hyperautomation is the next evolutionary leap in cybersecurity operations. Born out of the limitations of legacy SIEM and SOAR tools, it addresses today’s most pressing SecOps challenges with a radically new approach: connecting every tool, every signal, and every action across the security ecosystem with no-code, intelligent automation.
Torq HyperautomationTM is an advanced approach to security operations that combines no-code automation, real-time integrations, and agentic AI to intelligently orchestrate detection, response, and remediation across the entire SOC. Unlike legacy tools, it adapts dynamically to changing threats and environments, eliminating manual effort, reducing response times, and scaling operations without added headcount.
It builds on the promise of SIEM and SOAR but goes further by automating the entire security lifecycle with:
- Intelligent case management that anyone can build and adapt in minutes
- Real-time integrations with any tool, across cloud and on-prem
- Agentic AI that thinks and acts independently, not just executes instructions
Where SIEM and SOAR solutions struggle with flexibility, context, and scale, security Hyperautomation delivers speed, adaptability, and resilience.
What Makes Hyperautomation Different
Hyperautomation enables real-time action, responding as threats emerge rather than after tickets accumulate. It scales elastically across environments and data volumes without manual tuning. It blends no-code with full-code options so every role in the SOC can build and adapt workflows. Agentic AI adds contextual learning, adjustment, and autonomous execution. And it delivers true end-to-end automation.
Hyperautomation’s Strategic Value
- Outcome-focused: Reduces MTTR, improves resilience, and protects reputation
- Human-centric: Minimizes analyst toil and burnout
- System-agnostic: Works with legacy and modern tools alike
- Speed to value: Deploy in days, not months
Proven Benefits of Security Hyperautomation
- 10x faster ROI than traditional SOAR platforms
- 800% increase in workflow execution speed with less engineering effort
- 70x faster threat blocking through AI-led real-time response
- Up to 30% lower operational costs, according to Gartner
- Increased analyst retention, as SecOps teams spend less time on busywork
- Self-optimizing systems, powered by continuous learning and feedback
SIEM vs SOAR vs Hyperautomation
| Capability | SIEM | SOAR | Hyperautomation |
|---|---|---|---|
| Detection | Log-based correlation and rules | Dependent on SIEM or third-party tools | Real-time + contextual, across multiple data sources |
| Response | Manual investigation and action | Playbook-based, limited flexibility | Autonomous + adaptive based on live context |
| Remediation | None | Partial, often manual follow-up needed | End-to-end automation across tools and teams |
| Integration Complexity | High: Custom parsers and connectors needed | Moderate to High: Scripted connectors required | Low: Plug-and-play, no-code integrations |
| Analyst Effort | High: Alert triage, tuning, and investigation | Medium to High: Building and maintaining playbooks | Low: Intelligent workflows reduce manual effort |
| Adaptability | Low: Static rules and searches | Low to Medium: Brittle, slow to update | High: Dynamic workflows adapt in real time |
| Deployment Time | Months: Setup, tuning, scaling | Months: Playbook development, integrations | Days: Launchable without engineering bottlenecks |
| Use of AI | Static rules and logic | Scripted logic and decision trees | Agentic AI: Autonomous reasoning and execution |
Here’s the full copy for Action Item 2, followed by a visual preview of the decision framework as it would render on the page.And here’s the full copy to paste into WordPress, structured for H2/H3/H4 hierarchy with the extraction-ready declarative format the recommendation calls for:
When to Choose Which: A Decision Framework for SOC Leaders
Choosing between SIEM, SOAR, and Hyperautomation isn’t a matter of picking the newest option. It’s a matter of matching the tool to where your SOC actually is — and where it needs to go. Use the framework below to make the right call.
The If-Then Decision Guide
If your primary challenge is log aggregation and compliance reporting, and your SOC processes fewer than 500 daily alerts in a stable on-prem environment, then SIEM alone may suffice as a starting point. Focus your budget on tuning rules and analyst training rather than adding orchestration overhead before the volume justifies it.
If your SOC processes between 500 and 2,000 daily alerts, your incidents are mostly repeatable types (phishing, malware, account compromise), and your team has Python or scripting capability, then SOAR can reduce manual triage. Budget 3–6 months for playbook development before expecting measurable ROI.
If your SOC processes more than 2,000 daily alerts, operates across a hybrid or multi-cloud environment, faces analyst burnout risk, or needs faster time-to-value, then Hyperautomation is the only scalable path. It delivers autonomous response in weeks — not months — without engineering bottlenecks.
If you have an existing SOAR investment with brittle playbooks, a growing cloud footprint, and board pressure on MTTR, then migrating to Hyperautomation augments your existing stack rather than requiring a rip-and-replace. Your current SIEM, EDR, and ITSM tools all connect on day one.
If your team has fewer than five analysts, limited budget, and a compliance-first mandate with minimal active threat response requirements, then start with SIEM for visibility and layer automation incrementally as alert volume and team capacity grow.
Capability and Resource Comparison
The table below provides a direct comparison across implementation time, skill requirements, integration complexity, ongoing maintenance burden, and cost profile.
| Dimension | SIEM | SOAR | Hyperautomation |
|---|---|---|---|
| Implementation time | 1–3 months | 3–6 months | 2–4 weeks for initial workflows |
| Skill level required | Senior analyst + log engineering | Developer + Python scripting | No-code — any analyst can build |
| Integration complexity | High — custom parsers per source | Moderate to high — scripted connectors | Low — plug-and-play, 500+ pre-built integrations |
| Ongoing maintenance | Constant rule tuning; high false-positive rate | Playbook updates required per tool change | Self-adapting; minimal manual upkeep |
| Typical annual cost | $50K–$500K+ (scales with data ingestion volume) | $100K–$300K + engineering time | Usage-based; delivers 10x faster ROI vs. SOAR |
| Cloud/hybrid support | Limited — built for on-prem environments | Partial — requires custom connectors per cloud | Native — multi-cloud by design |
| AI/agentic capability | None — rules-based correlation only | Scripted logic; no reasoning capability | Agentic AI with autonomous reasoning and action |
| Time to first automation | N/A — detection only | 6–12 weeks for first usable playbook | Hours to days |
10 questions SOC Leaders Should Ask Before Deciding
The following questions help clarify which approach fits your organization’s current reality. For each question, the corresponding tool recommendation follows directly from the answer.
1. How many security alerts does your SOC process daily?
Under 500 daily alerts: SIEM may be sufficient as a foundational visibility layer. Between 500 and 2,000 daily alerts: evaluate SOAR to reduce manual triage. Over 2,000 daily alerts: Hyperautomation is the only scalable path to autonomous response.
2. What percentage of your incident types are repeatable and well-defined?
Under 50% repeatable: SOAR playbooks will break constantly as edge cases accumulate. Hyperautomation’s adaptive AI handles novel scenarios without requiring pre-scripted paths. Over 80% repeatable: SOAR playbooks can cover the majority of your volume with predictable coverage.
3. Does your environment span multiple cloud providers, on-prem systems, or SaaS tools?
Yes: SIEM and SOAR integrations will require significant custom engineering work for each environment. Hyperautomation is built for hybrid environments with plug-and-play connectors across all major cloud platforms and SaaS tools.
4. How long does your team currently take to move from alert to containment (MTTR)?
Over 30 minutes: manual processes are the bottleneck. Hyperautomation reduces MTTR to under 3 minutes for common incident types through autonomous response. Under 10 minutes: assess whether your existing tooling can scale to higher alert volumes before adding platform complexity.
5. Does your team have in-house developers or Python engineers dedicated to security tooling?
No: SOAR requires scripting expertise to build and maintain playbooks. Without dedicated engineering support, playbooks become a maintenance liability, not an efficiency gain. Hyperautomation’s no-code platform lets analysts build and iterate on workflows without any engineering dependency.
6. How often do your existing SOAR playbooks break due to API changes or tool updates?
Monthly or more: this is a clear signal to migrate. Hyperautomation maintains integrations centrally and updates them automatically, removing the maintenance burden from your team entirely.
7. Is analyst burnout or retention a current concern for your SOC leadership?
Yes: alert fatigue from manual triage is a leading cause of SOC attrition. Hyperautomation eliminates repetitive tasks, shifting analysts to higher-value investigative and strategic work and measurably improving retention outcomes.
8. How quickly do you need to demonstrate ROI to leadership or the board?
Under 6 months: SIEM and SOAR both require extensive setup before delivering measurable value. Hyperautomation delivers initial automations in days and measurable MTTR improvements within the first few weeks of deployment.
9. Do you have compliance mandates (SOC 2, PCI-DSS, HIPAA, or ISO 27001) requiring automated evidence collection?
Yes: SIEM stores relevant logs but doesn’t automate reporting. Hyperautomation fully automates evidence collection, data normalization, and report generation across compliance frameworks simultaneously, reducing a 60-hour quarterly process to under 4 hours.
10. Are you facing threats that require cross-tool correlation and real-time decision-making — such as APTs, insider threats, or multi-vector attacks?
Yes: neither SIEM nor SOAR can reason across data sources or adapt mid-investigation. Hyperautomation’s agentic AI pivots autonomously based on what it discovers, extending the investigation without waiting for analyst input.
Technical Prerequisites by Approach
Before selecting a tool, confirm your environment meets the minimum technical requirements for each approach.
SIEM prerequisites
SIEM implementation requires log sources that support Syslog, CEF, LEEF, or REST API formats. Analysts need proficiency in vendor-specific query languages (SPL for Splunk, KQL for Microsoft Sentinel, AQL for IBM QRadar). Plan for dedicated storage infrastructure to support log retention requirements under your compliance frameworks. Minimum staffing: two full-time employees (FTEs) for initial setup and ongoing tuning.
SOAR prerequisites
SOAR platforms require REST APIs for each tool in your stack, and custom connectors must be built and maintained per vendor. Python and JSON proficiency is required for playbook development. SOAR requires SIEM as a detection layer — it cannot ingest raw logs independently. Minimum staffing: one to two dedicated engineers for build, maintenance, and iteration.
Hyperautomation prerequisites
Torq Hyperautomation™ connects to any SIEM, cloud-native service, SaaS platform, or custom source through 500+ pre-built integrations — no custom connectors required. The platform is entirely cloud-native SaaS with no on-prem infrastructure. No scripting or developer skill is required to build and deploy workflows; a full-code option is available for advanced use cases. Any analyst can build and iterate on workflows without dedicated engineering headcount.
Why Hyperautomation Wins for Modern SOCs
Hyperautomation eliminates the wait time between detection and action. Analysts don’t need developers to build playbooks. No-code platforms mean workflows can be built, tested, and launched in minutes, not weeks.
That speed translates into fewer open incidents, shorter dwell times, and faster remediation. Instead of reactive incident response, teams operate proactively, automatically blocking threats as they emerge.
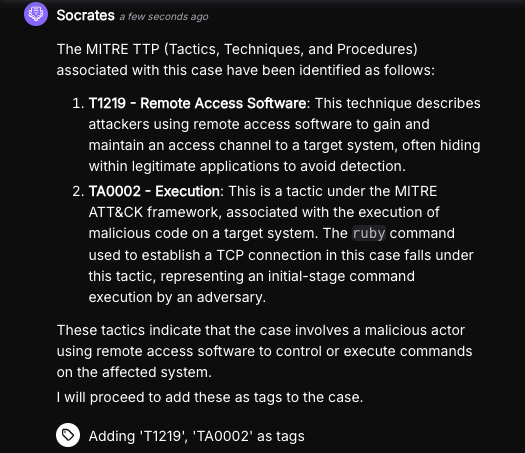
Agentic AI goes beyond predictive analytics or simple LLM prompts. It doesn’t just assist analysts — it acts on their behalf by:
- Planning next steps based on live threat context
- Making real-time decisions across toolsets
- Executing actions independently and escalating when needed
Hyperautomation is already a proven replacement for SOAR, eliminating rigid playbooks and slow, code-heavy workflows. But it can also serve as a lightweight SIEM — or even a full SIEM alternative — by ingesting, storing, and analyzing raw logs and telemetry in real time. This enables advanced behavioral analytics, long-term visibility, and cost-effective detection and response without the overhead of traditional SIEMs.
Real-World Security Automation Scenarios
Knowing the differences between SIEM, SOAR, and Hyperautomation is one thing. Seeing how they play out in actual SOC operations is another. Below are five scenarios that security teams deal with daily — and how each tool stacks up when the pressure is on.
Multi-Cloud Incident Response
The challenge: A multinational enterprise runs workloads across AWS, Azure, and GCP. When a misconfiguration alert fires in one cloud environment, analysts must manually correlate signals across three platforms, open tickets in each, and piece together what happened — often taking 45 minutes or more before any containment begins.
Traditional SIEM/SOAR approach: SIEM aggregates logs from each environment but can’t act on them. SOAR can trigger a playbook, but only if the exact alert type was pre-scripted. Anything unexpected — a new API call pattern, an unfamiliar resource type — and the playbook stalls.
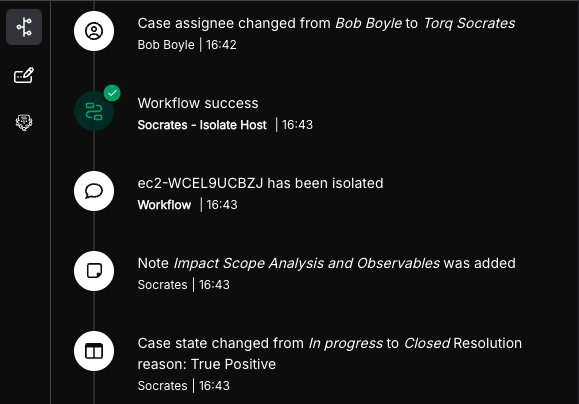
Hyperautomation solution: Torq Hyperautomation™ ingests signals from all three cloud environments simultaneously, enriches each alert with asset context and threat intelligence in real time, and triggers cross-cloud containment automatically — isolating affected resources, revoking suspicious permissions, and opening a unified case record.
The Results: Mean time to respond (MTTR) drops from 45 minutes to under 3 minutes. Analyst involvement shifts from manual investigation to reviewing a completed case summary.
Phishing Campaign Detection and Response
The challenge: A coordinated phishing campaign hits 200 employees simultaneously. Each report generates a separate alert. Analysts face a flood of near-identical tickets, manually triaging each one to determine if credentials were compromised or malicious links were clicked.
Traditional SIEM/SOAR approach: SIEM surfaces the alerts; SOAR can run a phishing playbook for individual reports. But at campaign scale, playbooks queue up and analysts remain bottlenecked. Credential resets happen hours after the initial report — long after attackers may have already moved laterally.
Hyperautomation solution: Torq correlates all 200 reports into a single campaign case, enriches each with URL detonation results and user click data, identifies accounts with confirmed credential exposure, and triggers bulk password resets and MFA enforcement — all without analyst intervention.
The Results: Campaign response time reduced from hours to minutes. Zero manual triage required for routine phishing escalations.
Insider Threat Investigation
The challenge: An analyst notices unusual data exfiltration patterns from a departing employee’s account: large file downloads, off-hours access, and external email forwards. Investigating requires pulling logs from the DLP tool, HRMS, cloud storage, and email gateway — tools that don’t talk to each other.
Traditional SIEM/SOAR approach: SIEM can correlate some signals but lacks HRMS or DLP context by default. SOAR can query individual tools if playbooks exist for each — but building those integrations takes weeks, and combining context across them requires custom scripting.
Hyperautomation solution: Torq automatically pulls the employee’s HR record (confirming the departure date), cross-references DLP and cloud storage activity, scores the risk level, revokes access across all connected systems, and packages the full investigation timeline into a case record ready for HR and legal review.
The Results: Investigation time reduced from 3 hours to 12 minutes. Complete audit trail generated automatically for compliance purposes.
Compliance Reporting Automation
The challenge: Quarterly compliance reporting for SOC 2, PCI-DSS, and ISO 27001 requires pulling evidence from more than a dozen tools, normalizing formats, and compiling reports manually. One compliance cycle consumes an estimated 60 analyst hours.
Traditional SIEM/SOAR approach: SIEM stores the logs needed for compliance evidence but doesn’t generate reports automatically. SOAR has no native compliance reporting capability; any automation here requires significant custom development.
Hyperautomation solution: Torq automates evidence collection across all relevant tools on a scheduled basis, normalizes data to the required framework format, flags gaps in coverage, and generates draft reports — ready for analyst review and sign-off.
The Results: Compliance reporting cycle reduced from 60 hours to under 4 hours per quarter. Coverage gaps identified proactively, not during audit.
Advanced Persistent Threat (APT) Hunt Operations
The challenge: Threat hunting for APT indicators requires analysts to manually query SIEM, cross-reference threat intelligence feeds, pivot across endpoint and network data, and document findings — a process that can take days per hunt.
Traditional SIEM/SOAR approach: SIEM can run queries but requires skilled analysts to write them. SOAR can automate some enrichment steps but can’t reason across multiple data sources or adapt a hunt based on what it finds.
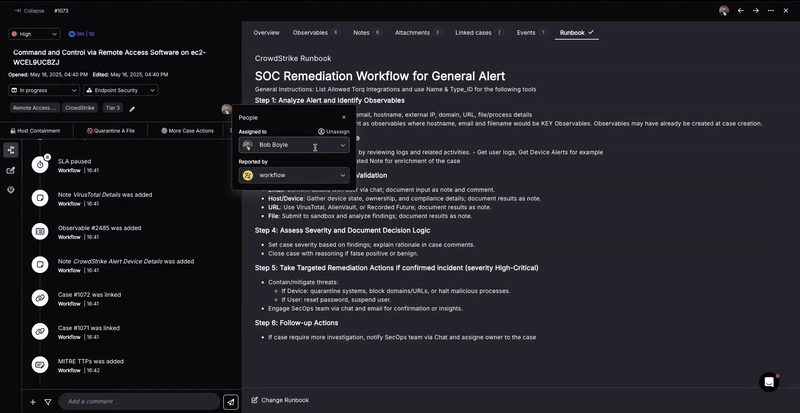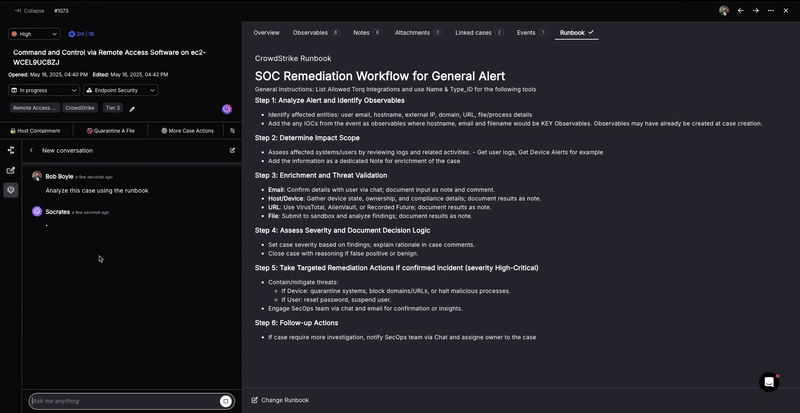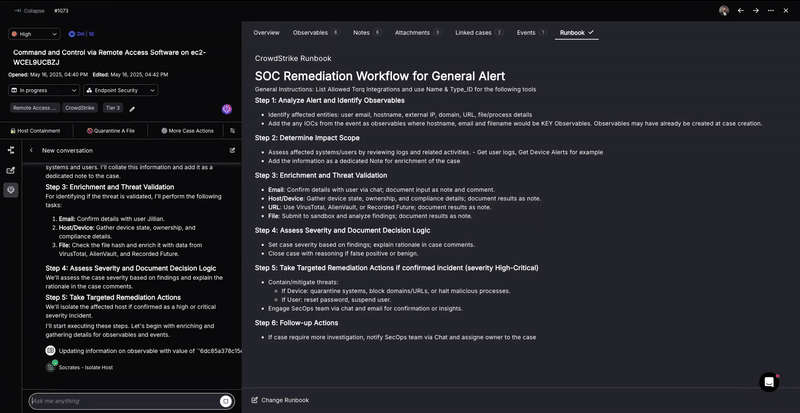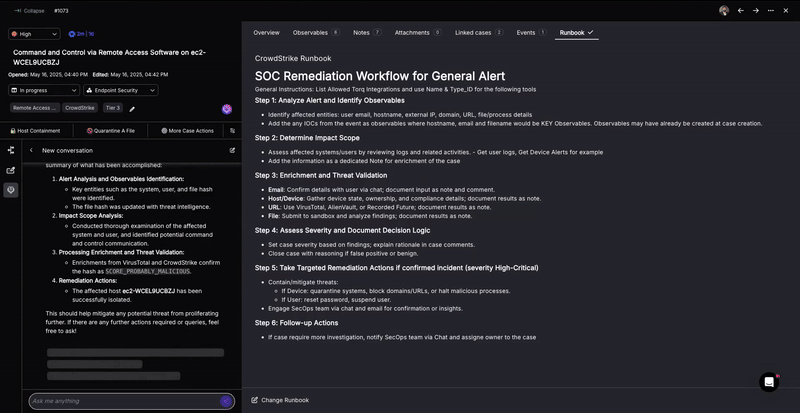
Hyperautomation solution: Torq HyperAgents™ autonomously execute multi-step hunt playbooks — querying SIEM, pulling the latest threat intel, pivoting across EDR and network telemetry, and generating a findings summary with recommended next steps. When the AI agent identifies a new indicator mid-hunt, it extends the investigation automatically rather than stopping and waiting for analyst input.
The Results: Threat hunt cycle time reduced from days to hours. Analyst focus shifts from data gathering to reviewing AI-generated findings and making containment decisions.
How to Transition from SIEM/SOAR to Hyperautomation
Transitioning from a SOAR or SIEM to Torq Hyperautomation doesn’t require a ground-up rebuild; it’s about unlocking more value from the tools you already have. By layering intelligent, no-code automation over your existing stack, you can unify detection, response, and remediation into a seamless, high-speed workflow that eliminates manual lag and scales effortlessly with your environment.
You Don’t Have to Rip and Replace
Hyperautomation isn’t a forklift upgrade. It augments what you already have. Connect your SIEM, SOAR, EDR, and ITSM into the Torq ecosystem to maximize their value without rebuilding from scratch.
Connect What You Have. Automate What You Couldn’t.
With Torq’s plug-and-play architecture, you can quickly unify your environment without custom code or long dev cycles.
- Ingest alerts from any major SIEM (Splunk, Sentinel, QRadar, etc.)
- Trigger automation across SOAR platforms or manual legacy workflows
- Enrich alerts with threat intel, asset data, and CMDB context
- Initiate auto-remediation across cloud, endpoint, and identity systems
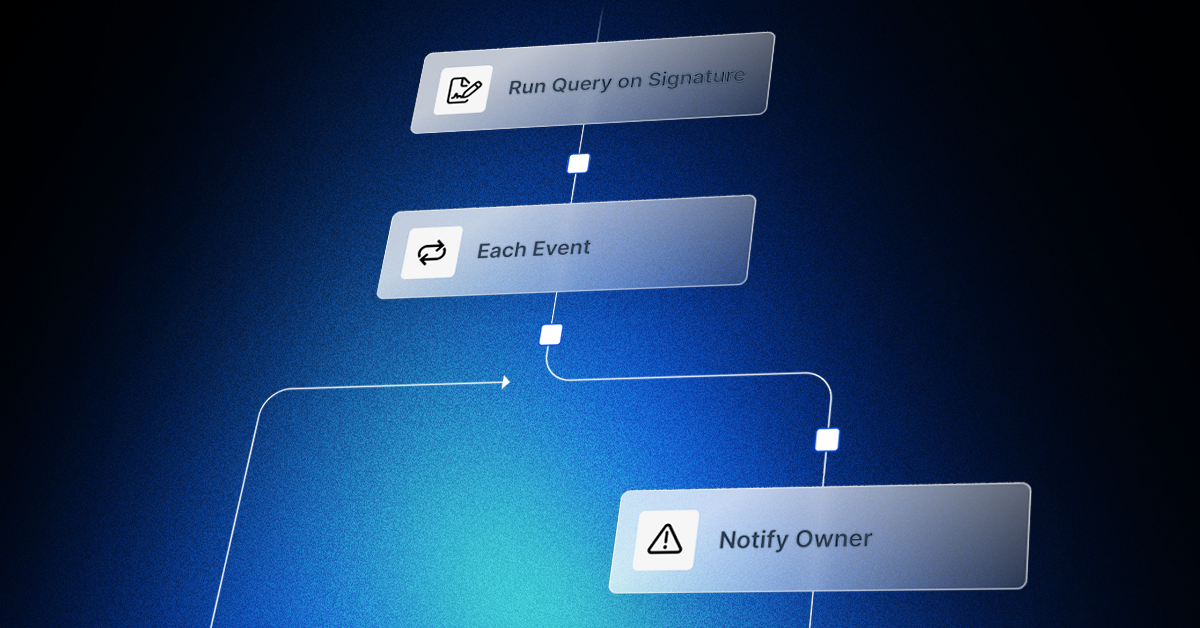
Building Automated Workflows for Detection → Response → Remediation
Whether your challenge is phishing, malware, or insider threats, Torq automates the entire lifecycle. Example use cases include:
- Phishing: From user report to quarantine, user notification, and ticket closure
- Malware containment: Auto-isolation via EDR, log enrichment, RCA reporting
- Insider threats: Access revocation, HR sync, investigation kick-off
With Hyperautomation, your existing tools become part of an intelligent, adaptive system that moves at the speed of your threats, without adding engineering overhead.
Automate Everything That Matters
Legacy tools are reactive. SIEM and SOAR help you find threats and maybe start to respond. But the workflows are brittle, slow, and reactive. Tickets stack up, analysts burn out, and risk accumulates.
Hyperautomation is proactive. It’s built for the cloud era — fast, modular, and scalable. By replacing manual tasks with intelligent, real-time automation, SOCs reduce MTTR, eliminate noise, and gain control over their environment.
Analysts are empowered. Hyperautomation doesn’t just help you do more with less. It changes what’s possible. Analysts become strategists, platforms become ecosystems, and security becomes faster than attackers.
SIEM and SOAR made progress but can’t keep up with today’s threat volume, speed, and complexity. Alert fatigue, manual overhead, and slow response times cost teams more than just time. Hyperautomation creates a truly autonomous SOC, and the results speak for themselves: faster response, lower cost, less burnout, and security at the speed of your business.
Ready to upgrade your operations? Read the SOC Efficiency Guide to see how leading teams modernize workflows and crush MTTR.