Making a real difference for our users with Generative AI
It has been over a year and a half since the latest generative AI revolution descended upon the world. All IT markets have seen a wave of both new AI products, as well as AI-driven capabilities in existing products being introduced with a breakneck pace. While most of them clearly perform things that, until recently, could have been described as “pure magic” even by the most cynical audiences, many questions can be raised regarding these capabilities being truly directed at transforming the customer experiences and outcomes vs. just being “mega cool.”
What’s wrong with “tech first”
Let’s take one step back. Allow me to introduce myself: I am a proud serial entrepreneur, having successfully established and grown two companies (one of which was acquired by a major player in the enterprise cybersecurity market).
When learning “entrepreneurship 101” – not a formal discipline, of course, but rather a collective experience of a community of entrepreneurs – I was told that establishing a cool (or even a unique) technical capability and then searching for a problem to apply it to is not a great idea. In the entrepreneurial world this is referred to as the “tech first” approach to establishing a product or a company, and it has been proven inferior to a “problem first” approach, where one identifies a problem and then considers various alternatives on how to solve it.
The collective experience of the past 2-3 decades has clearly shown that “problem first” products and companies have greater chances of generating long-lasting outcomes for their customers, and, therefore, have greater chances of establishing significant growing businesses. Tech first, on the other hand, might find a lot of support among the “romantics” of the technology, who enjoy technical capabilities because of what they can deliver, but might find it difficult to drive significant impactful outcomes.
Should we wait for a problem to present itself?
Does the above mean that every time a new technological barrier is being broken (just like it happened with the recent advancements in generative AI) we need to wait for the problems to present themselves and only then try to apply the new technology?
Of course not. The problems exist everywhere in the world and in different markets today. It is only a matter of picking the right (worthy of solving) problem and researching whether it can be solved to a better extent with the new technology (in comparison to existing solutions).
When deciding on a problem to pick, therefore, it is important to understand the components of it, and not just the general “headline,” such as:
- Who are the target audiences, i.e., the people or organizations having the problem? What are the unique characteristics of those who have it vs. those who don’t?
- How severe is the problem? How critical will solving the problem be for the target audience?
- What do these audiences do today? Do they have alternative solutions? How will our solution be better?
Finally, specifically when applying generative AI to certain problems, one of the most important questions to ask is: what would be the role of AI in the solution? Answering this question correctly is critical not only for creating the capability, but also for its future defensibility vs. the competition.
The role of AI in the solution
So what role does an AI play in the overall solution? Is there a real value in the integration of generative AI into the product environment, or is it just a “thin layer of glue” connecting mostly “off the shelf” Large Language Model (LLM) to the existing product “just for the cool effect?”
In my humble opinion, there is a huge difference between just bringing “some” AI capabilities into the UI of an existing product by integrating with one of the available off-the-shelf generative AI services and truly extending the unique technology in one’s product with AI.
Does the AI-driven capability rely on some rich, unique, or powerful technology that exists in the product, or does it simply come “on its own” without deep ties to the underlying tech? Does the capability perform additional functions on top of or integrated with “sending information to an AI and receiving the response” or is it mainly about interfacing with AI?
The answers to the above questions distinguish between an impactful and defensible technology and a cool thin layer of “AI”.
Case in Point: AI-driven automation workflow generation
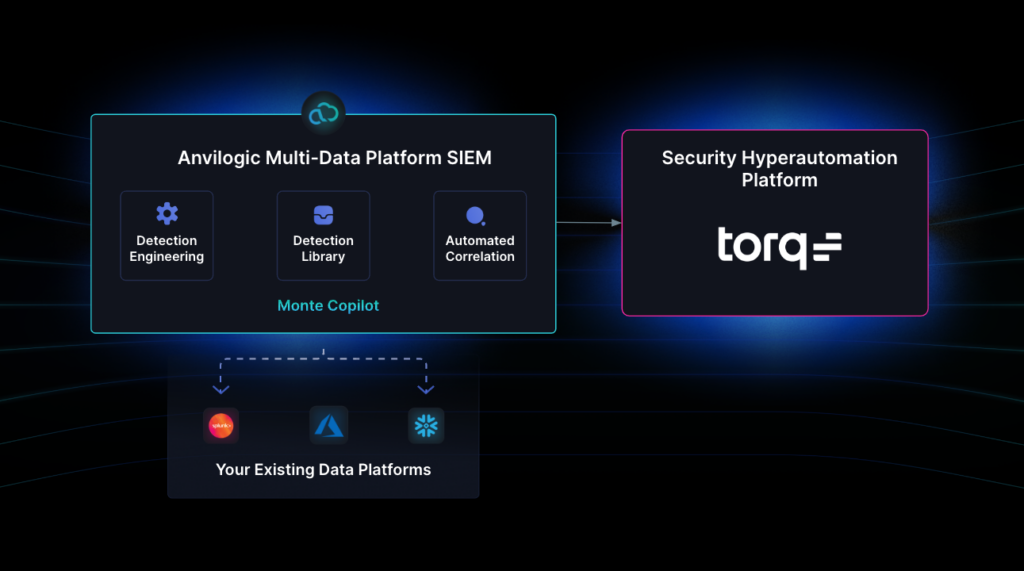
During the past year Torq has released 5 different AI-powered capabilities inside the product:
- Automatic generation of advanced data transformation and cloud platform management actions (in Torq workflows)
- Automatic generation of a documentation for complex automated processes to improve team collaboration
- Generation of workflow structure and data flow based on natural language description of the use-case
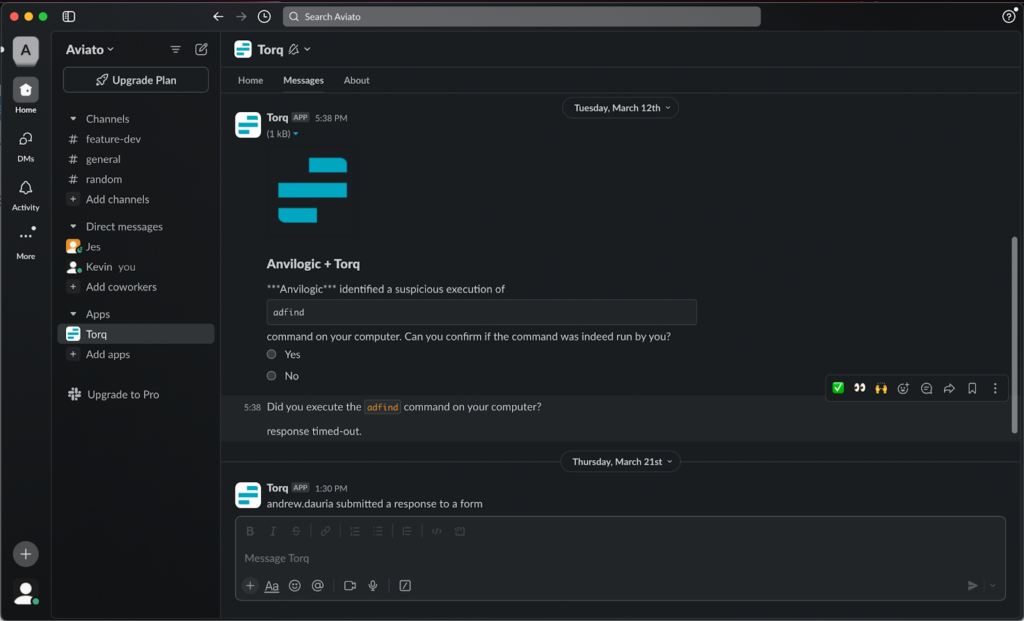
- Natural-language agent for security Case Management (a.k.a. Torq Socrates)
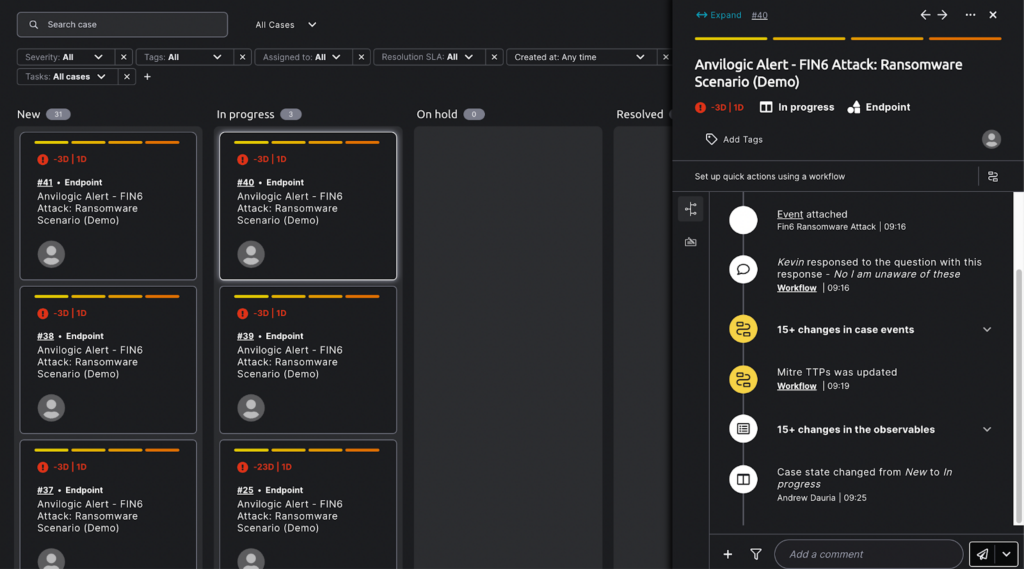
- Automatic summary for complex security cases to improve SOC analysts collaboration
As always, each of these has undergone a deep ideation process, involving not only our product leaders, but also our close partners, in order to ensure delivering important outcomes to our users.
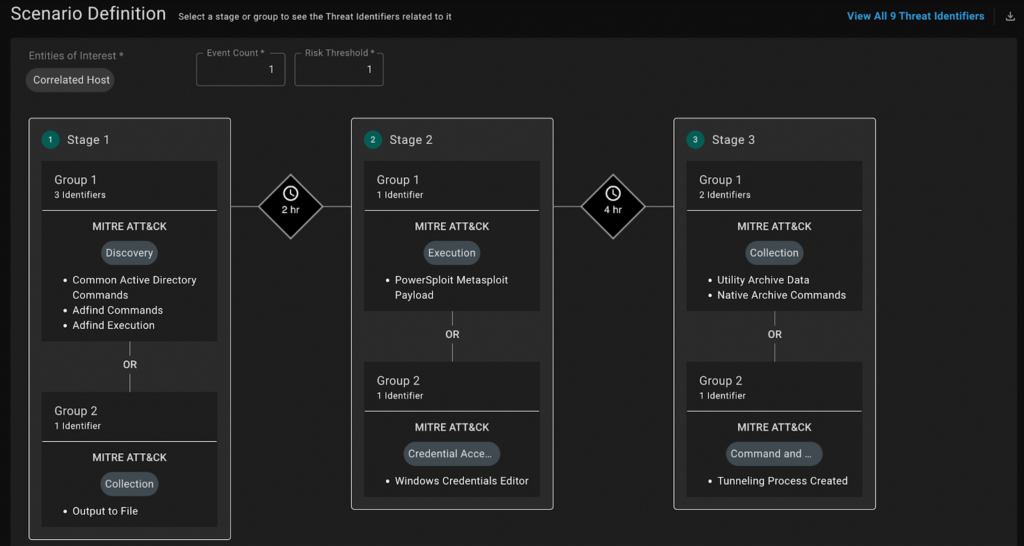
The basic capability allows the person wishing to build an automated workflow expressing their needs with a native language prompt. For example: “For every threat coming from my EDR, enrich its data with my Threat Intelligence systems and if the risk score is greater than X, take actions A,B,C to contain the threat”. After receiving the goals in such form, the system would automatically generate a Torq workflow based on the provided specifications that is close to being deployed to production after a quick review cycle.
While the above is a correct answer to the question “what is it doing?” it cannot drive the development of the capability without the consideration of challenges and problems experienced by a certain audience. In our case, we decided to double-down on accessibility of security automation for audiences of different technical abilities. Furthermore, we studied the ramp-up process of thousands of users developing security automation with Torq today, identifying existing gaps and focusing on rectifying the situation. Specifically, we realized that, as Torq becomes more sophisticated and feature-rich as a platform for developing automations, the task of finding the right and the most efficient way to implement a certain process becomes more challenging.
- The above has led us to a more focused definition of what we were looking for: a way to allow more people who are ramping up their security automation skills translate their ideas faster to fully-working and efficient automation workflows. Taking this challenge and breaking it down into components has clarified the main challenges that we needed to address.
Armed with the breakdown of required capabilities, we studied components that we already had in our product that should be leveraged to deliver the solution and identified gaps where AI could bring some critical game-changing value.
Thankfully, we had previously made a significant technological investment in the following:
- Thousands of predefined “smart” actions that can be reused in different security processes
- Carefully curated metadata explaining each such action in natural language, alongside possible usage variations and output examples
- Reusable process templates that combine above mentioned actions into consistent processes driving to specific security outcomes
- Unique extensibility architecture allowing flexible data retrieval and manipulation mechanisms, among other things
Building on top of the above technologies and leveraging generative AI for smart semantic analysis of natural language tasks, as well as for creating logical connections between consequent steps of automated processes has allowed us to deliver a uniquely powerful and flexible capability that stands out in terms of the value it provides. While the large language models we used for the task are trained on a generic set of data and can serve other solutions and not only Torq, the unique connective tissue are the data points and technologies mentioned above. These are the ones that ensure that the capabilities we deliver support the outstanding differentiation that Torq platform provides to its customers.
Summary
Having defined “product excellence” as a core value of our company, we are constantly on the lookout for innovation that can increase the outcomes we are delivering to our customers. Leveraging generative AI as a “tool” in our arsenal has allowed us to deliver multiple important innovations (and, BTW, if you are reading this blog, then stay tuned for more exciting things to come), but it is critical to view it as an important capability and continue building things targeted at solving user needs, rather than “trying to glue to AI into the product.”
P.S. This blog has been written entirely by human beings. No AI involved. Why? Not sure, but it felt like it would turn out more genuine this way.