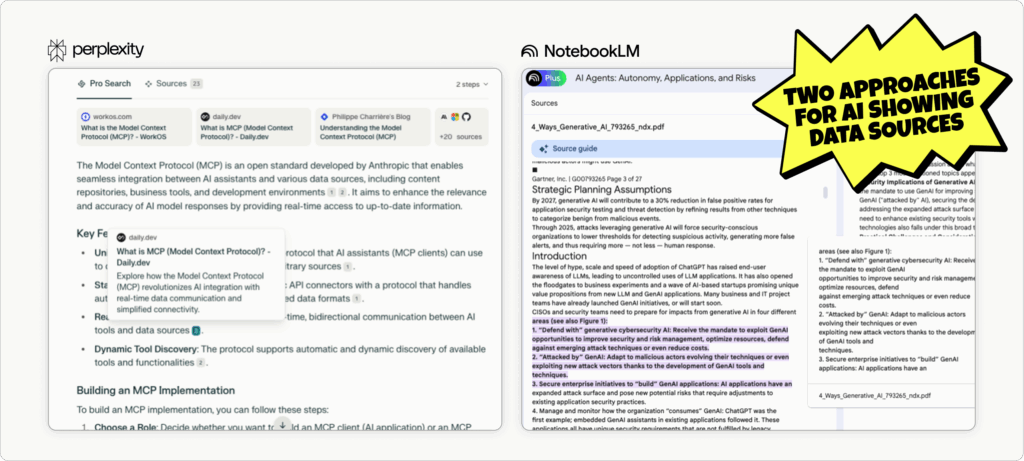
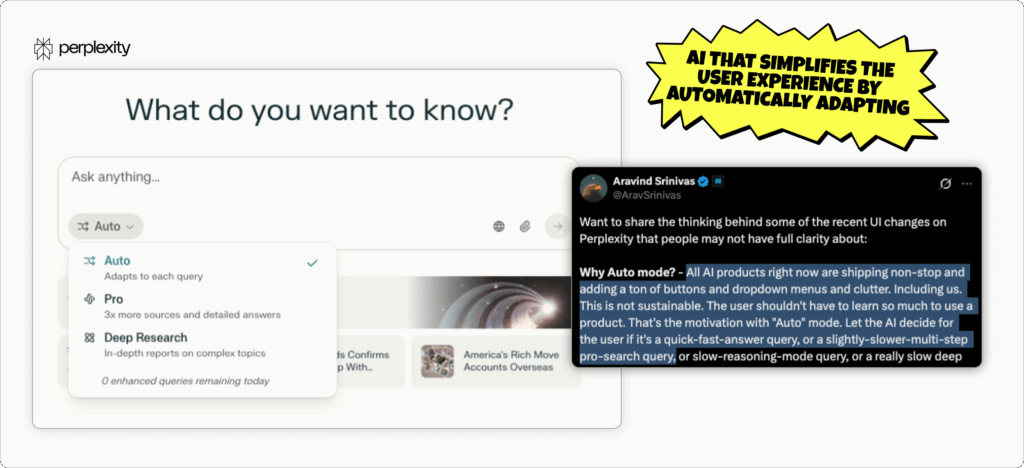
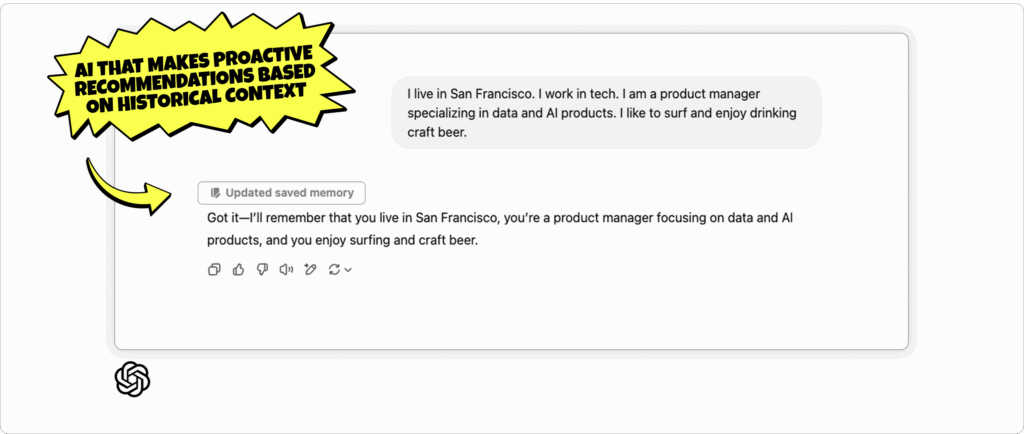
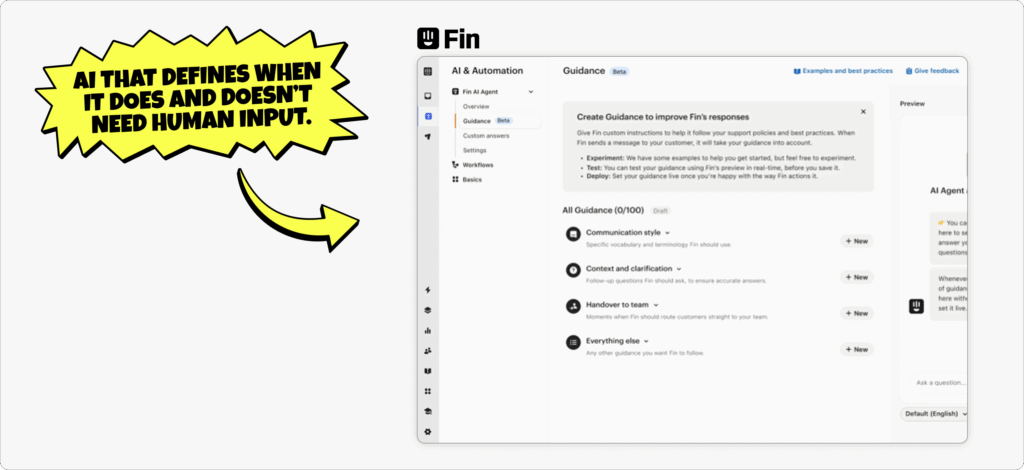
The modern threat landscape doesn’t scale down just because your team is lean. Whether you’re a two-person SecOps crew or a full-blown SOC, attackers don’t discriminate — and the alerts don’t stop.
Small security teams face the same phishing, ransomware, and insider threats as the world’s largest enterprises — only with fewer hands on deck and less time to respond.
To level the playing field, teams are turning to SecOps automation. With the right platform, automated SecOps lets lean teams move like fully-resourced ones — cutting through alert noise, accelerating response, and running workflows autonomously.
What Is SecOps Automation?
SecOps automation is the process using technology to streamline and automate the core workflows of security operations, including threat detection, triage, investigation, response, access control, and compliance reporting. It removes the manual work and alert fatigue that bog down security teams, enabling faster, more consistent, and more scalable operations.
While DevSecOps focuses on integrating security into the software development lifecycle, and ITOps automation targets infrastructure and IT service management, SecOps automation is laser-focused on protecting the business from threats.
Traditional SecOps Is Broken
Most security teams today are running on fumes. Threats are increasing, tools are multiplying, and analysts are stuck in an endless loop of triage and tuning as they face:
Too many alerts, not enough analysts: Security teams are drowning in noise. With limited headcount, it’s impossible to investigate everything, causing critical alerts to go unnoticed.
Poor tool integration: 51% of security leaders say their tools don’t integrate well, creating silos, manual handoffs, and slower response times.
Busywork over threat work: 46% of teams spend more time configuring and troubleshooting tools than mitigating threats. Another 59% say maintaining tools is the #1 inefficiency in their SOC.
It’s not sustainable — especially for lean teams.
Why Lean Teams Need SecOps Automation
Lean security teams are under pressure to deliver big results — without the benefit of big budgets, big headcount, or big enterprise infrastructure. They face the same volume of threats, alerts, and compliance requirements as a Fortune 500 but with a fraction of the resources.
SecOps automation bridges this resource gap. Deterministic automation workflows are ideal for the most common, repetitive, or predictable tasks, while non-deterministic workflows — augmented by agentic AI — enable understaffed SOC teams to handle more complex, multi-step security use cases more quickly and move towards an autonomous SOC.
SecOps automation significantly reduces manual overhead, accelerates threat response times, and empowers lean teams to run high-performance SOCs without the traditional overhead.
Five Ways Automated SecOps Helps Level the Playing Field
1. Phishing
Phishing is the most common form of cybercrime, with an estimated 3.4 billion spam emails sent daily. Each suspicious email requires triage, enrichment, investigation, and user outreach. Multiply that by dozens (or hundreds) of alerts a day, and you’re looking at full-blown burnout.
Automated SecOps turns phishing response into a self-contained workflow. From inbox monitoring and URL detonation to IOC lookups and automated takedowns, the entire lifecycle can be handled in minutes — not hours — without ever touching the analyst queue.
2. Threat Intelligence Enrichment
Threat intel is only useful if it’s fast, contextual, and operationalized — three things that don’t happen when analysts are manually switching between threat feeds and enrichment tools.
With SecOps automation, threat enrichment happens automatically. As alerts are ingested, automation pulls relevant context from multiple intel sources, correlates them with local data, and attaches insights to each case. That gives analysts a complete picture from the start.
3. Incident Response
Manual incident response is slow, error-prone, and hard to scale, especially with limited staff. Analysts have to piece together clues from multiple systems, coordinate handoffs, and manually document every action. For lean teams, it’s a recipe for delays and missed steps.
Automated incident response changes the game. As soon as an incident is detected, workflows kick off to contain the threat, collect forensics, notify stakeholders, and even auto-resolve based on pre-approved playbooks. With agentic AI in the loop, you can even triage, investigate, and remediate without any human intervention.
4. Vulnerability Management (VM)
Prioritizing which vulnerabilities matter is half the battle. But manually scanning assets, matching vulnerabilities to context, and assigning follow-up tasks can take days — assuming it gets done at all.
Automated SecOps streamlines the entire VM lifecycle. It ingests scanner output, correlates it with asset data, flags exploitable vulnerabilities, and initiates remediation workflows based on risk level — all without human touch. Analysts get real-time visibility into what’s fixed, what’s pending, and what’s critical.
5. Identity and Access Management (IAM)
Access creep and reused credentials are an open door for attackers — but they’re often overlooked because IAM tasks are tedious and time-consuming.
With automation, IAM becomes hands-free. Just-in-time access, automatic revocation, and periodic audits all run behind the scenes. You can even automate a response to suspicious activity, like impossible travel or privilege escalation, before an attacker has time to act.
SecOps Automation = Big Results for Lean Teams
Built for all skill levels: Low-code and no-code automation platforms have lowered the barrier to entry for security teams, making it easier for them to implement and manage security solutions. Analysts can build and deploy workflows without needing to write a single line of code, while more technical users can dig into scripting and APIs when needed. This flexibility empowers teams to move faster and focus on strategy instead of syntax.
Faster time to value with pre-built workflows: Many SecOps automation platforms offer prebuilt workflows for common use cases like phishing response and alert triage. These templates help teams launch fast, then iterate and customize for their environment.
Unified dashboards and reporting: Effective SecOps automation isn’t just about doing more — it’s about seeing more. Automation platforms often include built-in dashboards, visual workflow builders, and custom reporting tools that make it easier to track performance, prove value, and drive continuous improvement.
More use case coverage: Automation isn’t limited to incident response. Mature SecOps teams extend it to vulnerability management, insider threat detection, access controls, compliance audits, and even IT workflows like onboarding or offboarding. The more you automate, the more time your team has for strategic work.
Fully integrated AI access: It’s no secret that AI is the big hot ticket item in the cybersecurity industry. However, most organizations are diligently evaluating and carefully choosing when and where to deploy AI in their security stack — and rightfully so.
Whether you are slow-rolling AI access due to budget constraints or still building a business case to demonstrate the value of AI in the SOC to upper management, a SecOps automation platform provides a unique, centralized hub that fully integrates with every security solution, ensuring consistent and controlled AI access across your entire security environment.
Torq: The Leading Platform for SecOps Automation
Torq HyperSOC™ is the agentic AI-driven platform explicitly designed to empower lean security teams with extensive SecOps automation capabilities. Torq delivers:
Multi-Agent AI: Torq’s Socrates orchestrates automated workflows across specialized AI agents, seamlessly handling phishing triage, malware containment, IAM hygiene, and more.
Natural language workflows:No-code and low-code interfaces allow teams to launch and modify workflows simply by describing their intent, significantly accelerating adoption and effectiveness.
Rapid integration: Instant, seamless integrations across the entire security ecosystem eliminate silos, ensuring workflows operate fluidly across tools like AWS, Azure, Okta, SentinelOne, and many more.
Autonomous response: From detection to containment and remediation, Torq autonomously manages threats, dramatically reducing response times and enabling analysts to focus on high-impact tasks.
Check Point’s SOC faced a crushing alert load and a 30–40% manpower gap, until Torq HyperSOC™ came into the picture. Within days, Torq deployed over two dozen AI-driven playbooks that automated repetitive tasks, reduced alert fatigue, and enabled autonomous remediation for low-level threats. Now, analysts are empowered to focus on what matters, with NLP-powered case insights helping them make faster, smarter decisions.
This global fast-fashion giant replaced its legacy SOAR with Torq Hyperautomation™ to streamline security operations, cut alert fatigue, and simplify complex workflows across international teams. By automating end-user requests, case management, and just-in-time access, they reduced ticket resolution from days to minutes and saved a week of time per request.
Lennar’s SOC team replaced XSOAR with Torq to eliminate manual phishing remediation that used to take hours and is now resolved in minutes. With no-code and AI-powered workflow building, analysts of all skill levels can build automations and refocus on proactive threat hunting. Torq’s flexibility and speed also helped streamline asset management, cutting hours of work down to just minutes.
Scale Your Security Without Scaling Your Team
Torq HyperSOC™ enables lean teams to protect their businesses at enterprise scale, with automated SecOps workflows that eliminate manual drudgery, reduce response times, and enable analysts to focus on strategic threat hunting and high-value tasks.
Want to scale your security operations with Torq? Get a demo. And check out our Field CISO’s guide with practical advice for a more efficient SOC.
What are the first steps to implement SecOps automation for lean security teams?
Start with the workflows that consume the most analyst time for the least strategic value. For most teams, that means phishing triage and alert enrichment — two processes that are high-volume, repetitive, and well-suited for deterministic automation.
Map your current triage process end to end: where do alerts originate, what enrichment steps happen manually, and where do handoffs slow things down? That map becomes your first automation blueprint. From there, identify a platform that integrates with your existing stack without requiring a six-month deployment cycle. The best SecOps automation platforms offer pre-built workflow templates for common use cases, so you can be operational within days, not quarters.
Once your first few workflows are running, expand into incident response and case management. The goal isn’t to automate everything at once — it’s to free up enough analyst capacity that your team can start tackling higher-value work like detection engineering and threat hunting.
How much can SecOps automation reduce alert fatigue and response times?
Significantly — but the exact numbers depend on your starting point. Organizations that implement SecOps automation routinely report 80–90% reductions in mean time to respond (MTTR) for common alert types like phishing, endpoint detections, and identity-based threats.
Alert fatigue drops because automation handles the triage and enrichment steps that previously consumed analyst attention. Instead of manually investigating every alert, analysts see pre-enriched, prioritized cases with recommended actions — or, in many scenarios, the automation resolves the alert entirely without human involvement. According to Torq’s 2026 AI SOC Leadership Report, 94% of security leaders are already using AI in their SOC, and the teams seeing the biggest gains are the ones that pair deterministic automation with agentic AI for more complex, multi-step investigations.
The compounding effect matters too. Reducing response times on low-level alerts frees analyst capacity, which improves response times on high-severity incidents — the ones where speed actually determines business impact.
What's the typical ROI timeline for security operations automation?
Most teams see measurable ROI within 30 to 90 days of deployment, depending on complexity and the use cases they automate first.
High-volume, low-complexity workflows — phishing triage, alert enrichment, ticket creation — deliver value almost immediately because they replace hours of daily manual work. A team that automates phishing response alone can reclaim dozens of analyst hours per week, which translates directly into either cost savings or redeployed capacity for threat hunting and detection engineering.
More advanced use cases like automated incident response, vulnerability management, and identity lifecycle management take longer to build but deliver compounding returns. The key driver of fast ROI is platform accessibility: no-code and low-code automation platforms let security teams build and deploy workflows without waiting on engineering resources, which collapses the implementation timeline from months to weeks.
Which security processes should be automated first in a small SOC?
Prioritize by volume and repeatability. The processes that consume the most analyst hours with the most predictable steps are your best automation candidates.
For most small SOCs, the highest-impact starting points are phishing triage and response (the single biggest time sink for most teams), alert enrichment and deduplication (pulling context from threat intel feeds, SIEM data, and endpoint tools automatically), and ticket creation and case management (eliminating the copy-paste-and-pivot workflow that eats into every analyst’s day).
After those foundations are in place, expand into identity and access management — particularly just-in-time access provisioning and automated revocation — and vulnerability management workflows that correlate scanner output with asset criticality. The goal is to automate the undifferentiated heavy lifting so your analysts can focus on investigation, response, and proactive threat hunting — the work that actually requires human judgment.
How does AI-powered automation differ from traditional security automation?
Traditional security automation is deterministic: it follows predefined rules and executes the same steps in the same order every time. It’s powerful for well-understood, repeatable processes like enriching an alert with threat intel, creating a ticket, or revoking access. But it breaks down when the workflow requires judgment — when the next step depends on context that isn’t captured in a static playbook.
AI-powered automation adds a non-deterministic layer. Agentic AI can reason through multi-step investigations, analyze ambiguous data, prioritize competing signals, and make triage decisions that would otherwise require a human analyst. In practice, that means an AI-powered SecOps platform can not only enrich and route an alert, but also investigate it, determine whether it’s a true positive, recommend or execute a response action, and generate a case summary — all autonomously.
The most effective SecOps automation platforms combine both approaches: deterministic workflows for speed and consistency on known processes, and agentic AI for flexibility and judgment on the complex, multi-step use cases that previously required senior analysts.
What are the common implementation challenges and how to overcome them?
The biggest challenge isn’t technical — it’s organizational. Teams often stall on vendor selection, stakeholder buy-in, or trying to automate too much at once. The fix: start small, prove value fast, and expand from there. Pick one or two high-impact use cases, get them running, and use the time savings as your business case for broader adoption.
Integration complexity is another common blocker. If your automation platform requires custom connectors or professional services for every new tool, you’ll spend more time building integrations than building automations. Look for platforms with native, pre-built integrations across your security stack — SIEM, EDR, identity providers, ticketing systems, cloud infrastructure — so you can connect and automate without waiting on engineering.
Finally, teams sometimes underestimate the skill gap. Not every SOC analyst has scripting experience, and if only one person can build workflows, you’ve created a bottleneck. No-code and low-code platforms solve this by making automation accessible to analysts at every skill level, which distributes the workload and accelerates adoption across the team.
Traditional vulnerability management is falling behind. Manual workflows stall progress. Legacy SOAR drags teams down. Siloed tools leave dangerous gaps. The result is delays, blind spots, and risk exposure that compound fast. Human error and inefficiency are baked into the process, costing teams more than time. It’s compromising compliance, degrading customer experience, and overwhelming analysts.
It doesn’t have to be this way.
This blog breaks the vulnerability management lifecycle into six steps, each primed for automation. We’ll show you how to modernize your workflows using Hyperautomation and agentic AI. This is how modern SOCs move faster, respond smarter, and stay in control.
What is the Vulnerability Management Lifecycle?
Vulnerability management is the continuous process of identifying, evaluating, prioritizing, remediating, and monitoring security weaknesses (vulnerabilities) across an organization’s systems, networks, and applications. Its goal is to reduce the attack surface by proactively addressing vulnerabilities before cybercriminals can exploit them.
The vulnerability management lifecycle is a continuous, systematic process for identifying, assessing, prioritizing, remediating, and monitoring security vulnerabilities within an organization’s IT infrastructure. It’s a crucial part of any cybersecurity strategy, aiming to manage risks and minimize the potential for cyberattacks proactively.
The vulnerability management lifecycle includes:
Discovery of all assets in the environment
Assessment of vulnerabilities using automated scanners and threat intelligence
Prioritization based on factors like severity (i.e., CVSS score), exploitability, and business impact
Remediation or mitigation through patching, configuration changes, or compensating controls
Validation and monitoring to confirm fixes and detect re-exposure or new risks
Reporting and improvement to refine processes and boost efficiency
Today’s dynamic cloud environments demand more than reactive security. As modern IT environments grow more complex and dynamic, traditional approaches that rely on manual processes and fragmented tools can’t keep up. The rapid change in cloud infrastructure and the constant emergence of new vulnerabilities make it nearly impossible for security teams to identify and act on every risk in time.
Automating the vulnerability management lifecycle — across asset discovery, scanning, prioritization, remediation, and validation — helps teams move from reactive to proactive. By integrating data from scanners, threat intelligence platforms, Configuration Management Databases (CMDBs), and ITSM (IT Service Management) systems, automated workflows can continuously identify critical issues, assign ownership, and trigger remediation actions.
Organizations can ensure consistent, efficient, and scalable risk mitigation with a well-defined and automated vulnerability management program. The result is faster response, reduced exposure, improved compliance, and a more resilient security posture.
The 6 Steps of Vulnerability Management Lifecycle You Can Automate Today
Step 1: Asset Discovery and Vulnerability Assessment
Before vulnerabilities can be managed, organizations must first identify every asset in their environment. This step begins with building a complete, real-time inventory of IT assets — including endpoints, servers, cloud workloads, SaaS apps, IoT devices, and shadow IT — across on-premises, cloud, and hybrid environments. Critical vulnerabilities often go undetected without accurate asset discovery, leaving organizations exposed.
Once discovered, assets should be classified based on business importance, data sensitivity, and exposure level. Security frameworks like the CIS Controls or ISO standards can help guide this classification process to ensure consistent, policy-driven prioritization.
Vulnerability assessment follows closely behind discovery. Organizations conduct scheduled or continuous scans using tools like Qualys, Tenable, or Rapid7 to identify known vulnerabilities. Automated scans are augmented by penetration tests and configuration audits, which simulate real-world attack scenarios and uncover deeper misconfigurations that scanners might miss. These assessments provide the foundation for informed, risk-based decision-making in later stages.
Key metrics for this step include asset discovery completeness, vulnerability coverage rate, and time to discovery. Organizations that automate asset discovery and vulnerability scanning reduce blind spots, accelerate detection, and set the stage for a proactive vulnerability management lifecycle.
How Torq Can Automate This: Torq integrates with your asset inventory, CMDB, cloud providers, and endpoint detection tools to ingest asset data continuously. No-code workflows automatically reconcile discovered assets across hybrid environments, keeping your inventory current without spreadsheets or manual audits. Clients can also use Torq to trigger validation workflows when new, unmanaged assets appear, alerting security teams to take immediate action.
Step 2: Vulnerability Scanning and Detection
With assets identified and inventoried, the next step is systematic vulnerability scanning. Continuous scanning ensures that new vulnerabilities are identified immediately, not just during scheduled review windows. Modern scanners integrated with SIEMs, EDRs, and threat intelligence platforms can detect vulnerabilities and push findings into workflows.
Equally important is the normalization and automation of scan data. Without these key systems, teams often struggle to analyze findings from multiple tools or formats. Automated ingestion pipelines ensure scan results are normalized, deduplicated, and enriched with contextual metadata so teams can prioritize issues efficiently. This minimizes human error and eliminates manual data wrangling, allowing analysts to focus on threat mitigation rather than spreadsheet management.
How Torq Can Automate This: Torq connects directly to vulnerability scanners like Tenable, Qualys, and Rapid7 to ingest real-time scan results. It normalizes disparate data formats and enriches them with contextual metadata, like asset criticality, owner, and business function, then automatically routes findings into triage workflows. Torq eliminates bottlenecks by auto-tagging vulnerabilities based on severity, source, and exploitability, and escalating only the ones that matter.
Step 3: Risk-Based Vulnerability Prioritization
Not all vulnerabilities pose the same threat, and relying solely on Common Vulnerability Scoring System (CVSS) scores often wastes time and leads to missed priorities.
Effective vulnerability prioritization combines multiple factors: severity ratings, real-time threat intelligence, asset value, exploitability, and the potential business impact if compromised. A vulnerability on a public-facing application used by customers carries far more weight than one on an internal test server, even if their CVSS scores are identical.
This stage involves applying structure and strategy to vulnerability triage. It requires input from multiple systems and stakeholders and the ability to evaluate each vulnerability in context, not just in isolation.
How Torq Can Automate This: Torq automates prioritization by combining CVSS scores, threat intelligence, asset importance, and business impact. Risk-scoring models are baked into workflows that assign ownership based on asset tags or business unit and notify the right team instantly. AI Agents dynamically adapt prioritization workflows to changing threat intel, for example, reprioritizing based on active exploitation reports from MISP or Recorded Future.
Step 4: Remediation and Patch Deployment
Once vulnerabilities are prioritized, the next step is action — and this is where many organizations get bogged down. Patch management and remediation can be time-consuming, error-prone, and resource-intensive, especially when handled manually.
Coordinating patch deployment, configuration changes, and policy enforcement is complex. Different systems, ticketing queues, and ownership models often introduce delays that extend mean time to remediate (MTTR). Critical asset patching may sometimes be skipped entirely due to a lack of visibility or process bottlenecks.
The key to making remediation effective is ensuring it’s consistent, policy-driven, and well-integrated with existing IT and security infrastructure. Automated workflows streamline this process.
How Torq Can Automate This: Torq triggers auto-remediation actions the moment a vulnerability crosses a risk threshold. Whether that’s opening a ServiceNow ticket, deploying a patch through CrowdStrike, or updating firewall rules — Torq coordinates every step across ITSM, EDR, and config management systems. Torq lets you define remediation SLAs by risk level, then automatically tracks and escalates any patching delays.
Step 5: Validation and Continuous Monitoring
Even after a patch is deployed or a mitigation is applied, teams must validate that the vulnerability is truly resolved and that the fix hasn’t introduced new risks. Organizations can be left with a false sense of security without a clear validation process.
This step is also where continuous monitoring comes into play. Threats evolve, and systems change, meaning previously resolved vulnerabilities can resurface or emerge in the same risk areas. Keeping tabs on those changes in real time is essential to maintaining a strong security posture.
Beyond operational assurance, validation and monitoring also feed key performance indicators (KPIs). Metrics like mean time to validate, remediation success rate, and recurring vulnerabilities offer insight into program effectiveness and guide continuous improvement.
How Torq Can Automate This: Torq ensures that every remediation action is followed by automatic verification. It coordinates post-patch scans, checks system health, and updates real-time vulnerability status. If a scan fails or a system shows signs of re-exposure, Torq reopens the case and notifies the right teams.
Torq’s workflows also power continuous monitoring across your environment, triggering alerts and actions the moment new vulnerabilities are detected. All validation results are logged with full audit trails, giving teams a clear, compliant record of what was fixed, when, and how.
Step 6: Reporting and Improvement
The final — and often most overlooked — step in the vulnerability management lifecycle is reporting and continuous improvement. This stage turns tactical remediation work into strategic insight, enabling security teams to track performance, share results with stakeholders, and refine processes over time.
Effective reporting starts with capturing and consolidating key metrics from across the lifecycle. These include mean time to detect (MTTD), mean time to remediate (MTTR), validation success rate, outstanding vulnerabilities by risk level, and SLA adherence. Automation can generate these reports in real time, pulling directly from ITSM, scanning tools, and case management systems, eliminating manual data gathering and improving accuracy.
But reporting isn’t just about compliance dashboards or CISO updates. It’s also about communicating clearly across teams. Security analysts need detailed, technical data to investigate root causes. IT and DevOps teams need actionable task lists and timelines. Executives need business-aligned summaries showing risk reduction, operational efficiency, and ROI. Torq’s AI case summaries and customizable reports ensure the right insights reach the right people.
Beyond communication, this stage powers process improvement. Every vulnerability managed, every patch deployed, and every false positive investigated is an opportunity to learn. Were there delays in detection? Was ownership misrouted? Did remediation workflows succeed automatically, or require manual overrides?
Automation platforms like Torq can highlight bottlenecks, track repetitive tasks, and suggest optimizations for future cycles, helping teams evolve with the threat landscape.
How Torq Can Automate This: Torq aggregates lifecycle metrics — MTTR, patching trends, asset coverage, false positives, and more — into real-time dashboards. It automates reporting to different stakeholders (security, IT, execs) and uses historical data to optimize future workflows. With Torq’s intelligent case summaries and agentic AI analysis, your team gets metrics, insights, and improvement recommendations after every cycle.
Visualizing the Automated Vulnerability Management Workflow
The Automated Vulnerability Management Workflow
Each stage features integration points with standard security tools, all unified through no-code automation and adaptive AI workflows, ensuring seamless transitions between each lifecycle step.
How Torq’s No-Code, Agentic AI Transforms VM
Legacy SOAR platforms often promise automation — but deliver rigid, playbook-style workflows that break the moment something unexpected happens. They’re difficult to update, heavily reliant on code, and require constant upkeep to remain useful in fast-changing threat environments. Vulnerability management, in particular, suffers from this inflexibility. New CVEs emerge daily, patch windows shift, and business priorities evolve. Static systems simply can’t keep up.
Torq is built for the opposite. Its modern no-code platform empowers security teams to create and customize complex vulnerability management workflows — without writing a single line of code. Whether integrating with vulnerability scanners like Tenable or Qualys, orchestrating patch actions through CrowdStrike or SCCM, or syncing data across Jira, ServiceNow, and CMDBs — Torq makes it fast, repeatable, and reliable.
Where Torq truly sets itself apart is with agentic AI — purpose-built intelligence that doesn’t just execute tasks, but reasons through them. Torq’s agentic AI dynamically adjusts prioritization models based on live threat intelligence, changes workflows on the fly based on remediation delays or escalation policies, and even recommends new automation paths based on past actions and results.
This creates an entirely different experience:
No-code flexibility means teams can launch or modify vulnerability workflows in minutes, not days or weeks.
Dynamic response allows the system to reprioritize or reassign vulnerabilities as business needs or threat conditions shift.
Human-level reasoning lets agentic AI anticipate gaps or delays, take corrective action, and escalate intelligently, all without manual input.
By combining intuitive workflow creation with adaptive intelligence, Torq transforms the vulnerability management lifecycle from a slow, manual process into a fast, autonomous system. Teams can focus on strategy and oversight while Torq handles the orchestration, remediation, and validation at machine speed — all with full visibility and control. It’s not just automation — it’s Hyperautomation, designed for the pace and complexity of modern cybersecurity.
Reclaim Time. Reduce Risk. Automate Everything.
With Torq Hyperautomation™, every stage of the vulnerability management lifecycle becomes faster, more accurate, and radically more effective. Teams reclaim time, reduce risk, and stay focused on what matters: preventing the next security incident.
Ready to make the shift? Read the SOC Efficiency Guide to see how leading security teams accelerate response, eliminate alert fatigue, and scale operations with Torq.
Cybersecurity frameworks provide organizations with clear, actionable pathways to safeguard assets, ensure regulatory compliance, maintain robust security controls, and align security initiatives effectively. But while frameworks like NIST, ISO, and CIS provide a vital blueprint for security, implementing them is anything but straightforward. Manual processes, siloed tools, and resource constraints slow implementation and dilute impact.
Torq Hyperautomation™ eliminates the operational friction of security framework adoption. It connects your tools, automates repetitive control validation, and ensures your security program stays aligned, agile, and audit-ready.
Whether you’re building toward SOC 2, aligning to NIST CSF, or managing global compliance at scale, Torq transforms frameworks from static documents into living, responsive systems that secure your entire network.
Why Cybersecurity Frameworks Matter
A security framework is a structured set of guidelines, best practices, and standards designed to help organizations manage and reduce cybersecurity risk. It provides a repeatable methodology for identifying, protecting, detecting, responding to, and recovering from cyber threats, while ensuring alignment with regulatory, legal, and industry-specific compliance requirements.
A security framework outlines:
Security controls: Technical, administrative, and physical safeguards to protect systems and data
Risk management processes: How to assess and prioritize threats and vulnerabilities
Governance structures: Roles, responsibilities, and oversight mechanisms
Continuous improvement: Ongoing assessment, monitoring, and adaptation to evolving threats
Benefits of adopting a cybersecurity framework include:
Improved risk management: Frameworks provide comprehensive and established methods for identifying, assessing, and mitigating cybersecurity threats and vulnerabilities.
Enhanced compliance: Frameworks such as GDPR, HIPAA, and PCI DSS outline explicit guidelines for managing sensitive data, ensuring enterprises meet regulatory obligations and avoid costly penalties.
Streamlined security processes: Implementing standardized cybersecurity frameworks reduces complexity and enables more efficient security operations.
12 Common Types of Security Frameworks in 2025
Understanding the various security frameworks available is crucial for selecting the right approach tailored to your organization’s needs. Here are some of the most widely adopted cybersecurity frameworks:
SOC 2 (System and Organization Controls 2): A framework developed by the AICPA to evaluate service providers’ ability to manage customer data securely. It is based on five trust service criteria: security, availability, processing integrity, confidentiality, and privacy. SOC 2 is crucial for SaaS and cloud service providers handling sensitive customer data. It signals to clients and auditors that your organization meets strict standards for data handling and privacy.
GDPR (General Data Protection Regulation): A European Union regulation that sets strict requirements for data privacy and protection for any organization handling EU citizen data. GDPR impacts organizations worldwide due to its extraterritorial scope and severe penalties for noncompliance.
PCI DSS (Payment Card Industry Data Security Standard): A global standard for securing credit card transactions and sensitive payment data. It is mandatory for any organization that stores, processes, or transmits cardholder data.
HIPAA (Health Insurance Portability and Accountability Act): A U.S. regulation that establishes national standards to protect sensitive patient health information. It applies to healthcare providers, insurers, and business associates managing protected health information (PHI).
CIS Controls: A prioritized set of 18 best practices developed by the Center for Internet Security (CIS), designed to protect against the most common and dangerous cyber threats.
ISO 27001: An international standard for establishing, implementing, maintaining, and continually improving an Information Security Management System (ISMS). It’s one of the most comprehensive and certifiable frameworks available.
NIST SP 800-53: A catalog of security and privacy controls developed by the National Institute of Standards and Technology (NIST) for federal agencies and their contractors. It’s highly detailed and adaptable for enterprises seeking rigorous security control baselines.
NIST SP 800-171: Aimed at non-federal organizations, this framework outlines security requirements for protecting Controlled Unclassified Information (CUI). Often used by defense contractors and other government-adjacent enterprises.
NIST Cybersecurity Framework (NIST CSF): A voluntary framework designed to help organizations of all sizes manage and reduce cybersecurity risks. It consists of five core functions: Identify, Protect, Detect, Respond, and Recover.
NIST SP 1800 Series: A collection of practical, example-driven publications offering step-by-step guidance for implementing cybersecurity technologies, tailored for specific sectors and challenges.
COBIT: A framework by ISACA for governance and management of enterprise IT, aligning security with strategic business goals.
DORA (Digital Operational Resilience Act): A regulation introduced by the EU to ensure the financial sector’s operational resilience. DORA requires banks, insurers, investment firms, and other financial entities to manage and withstand risks.
How to Choose a Security Framework
Selecting an appropriate security framework requires careful consideration of several critical factors.
Understand your business context and requirements: Assess your industry, business size, regulatory landscape, and specific cybersecurity challenges.
Evaluate framework compatibility: Consider how easily the framework integrates with your existing technologies and security controls.
Prioritize scalability and adaptability: Ensure the chosen framework can grow with your organization and adapt to evolving threats.
Seek broad organizational support: Engage stakeholders across your organization, including IT, compliance, and executive teams, to ensure alignment and buy-in.
Leverage Hyperautomation for execution: Look for opportunities to operationalize framework controls using automation platforms like Torq. Automating control validation, policy enforcement, and evidence collection accelerates adoption and reduces long-term operational burden.
How to Navigate Security Framework Challenges with Torq
Implementing security frameworks can pose significant challenges for many organizations. Between legacy infrastructure, fragmented tooling, evolving threats, and limited resources, many organizations struggle to move from documentation to real-world execution. Torq Hyperautomation™ helps security teams overcome the most common framework adoption barriers by eliminating manual overhead and automating critical workflows. Here are some common challenges and how Torq helps solve them.
Integration with Existing Systems
Challenge: Legacy systems and fragmented security stacks can hinder effective integration of cybersecurity frameworks.
Torq Solution: Torq’s Hyperautomation Platform acts as the connection across your environment, integrating seamlessly with SIEMs, EDRs, ticketing systems, IAM tools, and cloud platforms. Whether you’re automating control testing, enforcing configuration standards, or orchestrating incident response, Torq streamlines the end-to-end flow of data and decisions. Drag-and-drop and AI-generated workflows and low-code/no-code interfaces empower teams to operationalize frameworks without developer bottlenecks.
Budget Constraints
Challenge: Many organizations have limited resources, which complicates the implementation of comprehensive security frameworks.
Torq Solution: Torq automates the grunt work of security operations. From mapping controls to running automated assessments, Torq eliminates repetitive tasks and minimizes the need for dedicated coding resources. Torq helps organizations achieve full framework alignment within days or weeks by reducing engineering dependencies and accelerating time-to-value. The result is lower operational costs and higher team productivity.
Torq Solution: Torq continuously adapts to changing threat conditions using telemetry, AI-driven enrichment, and dynamic workflows. When anomalies are detected, it can automatically trigger responses aligned to your framework requirements, whether that means escalating high-risk activity, revoking access, or triggering predefined mitigation playbooks.
Ensuring Compliance and Audits
Challenge: Maintaining ongoing compliance and being audit-ready at all times is challenging, particularly for global enterprises.
Torq Solution: Torq automates evidence collection, control validation, and documentation, ensuring compliance workflows are baked into daily operations. It creates a centralized audit trail of all actions taken, complete with timestamps, enriched context, and mapped framework references. Whether preparing for an internal review or a third-party audit, Torq gives your team a single source of truth that’s always up to date and defensible.
Why Torq?
Torq Hyperautomation is built to operationalize security frameworks at scale. It delivers:
Contextual automation that adapts to evolving threats and compliance needs
Framework-aligned workflows that are repeatable, measurable, and audit-ready
Enterprise-grade security with RBAC, logging, version control, and policy enforcement
Whether you’re building toward SOC 2, aligning to ISO 27001, or navigating NIST 800-171 requirements, Torq makes it faster, easier, and more cost-effective to meet your goals.
Operationalizing Security Frameworks with Hyperautomation
For many organizations, cybersecurity frameworks exist primarily as static documents, useful for audits, but disconnected from daily security operations. The result is an execution gap: security teams know what they should be doing but lack the tools to enforce those controls in real time. This is where most frameworks fall short.
With Torq Hyperautomation™, security frameworks are no longer theoretical. Every control, requirement, and guideline can be translated into automated workflows that enforce compliance continuously across your environment.
Torq brings security frameworks to life:
Control mapping: Connect framework controls to specific, repeatable workflows. Based on your framework’s requirements, automate user access reviews, policy enforcement, or data loss prevention.
Continuous monitoring: Instead of relying on periodic assessments, Torq continuously validates whether controls are being followed, flagging drift immediately and triggering corrective action before gaps become risks.
Automatic documentation and evidence collection: Every action is logged, timestamped, and mapped back to the corresponding framework control. That means when audit time comes, all the evidence is already there.
Case management: Framework-driven alerts or incidents (e.g., a failed backup, an unauthorized access attempt) are automatically routed into case management workflows. Analysts can investigate, respond, and document resolutions, ensuring nothing falls through the cracks.
Make Cybersecurity Frameworks Work for You
Security frameworks are essential to building a resilient, compliant, and threat-ready enterprise, but only when they’re effectively operationalized. Too often, organizations get stuck in manual processes, fragmented tools, and misaligned controls, turning frameworks into paperwork rather than real protection.
By combining powerful Hyperautomation with deep integration across your security stack, Torq brings cybersecurity frameworks to life. It ensures your organization isn’t just aligned to standards like NIST, ISO 27001, or SOC 2 but actively enforcing them in real time.
From automating evidence collection and incident response to dynamically adapting to new threats, Torq empowers your security teams to move faster, reduce costs, and improve outcomes, without compromising control or compliance.
Security Operations Centers (SOCs) continue to struggle in 2025. The perfect storm of growing alert volume, consistent talent shortage, and the well-documented limitations of legacy SOAR solutions have brought many SOC teams to a breaking point. At the same time, bad actors continue to innovate, and cybercriminals have become more sophisticated in their tactics and techniques, including using AI to launch attacks at scale.
Fortunately, AI in the SOC has begun to revolutionize the security operations field, specifically in the area of Tier-1 security analysis. According to Gartner, “By 2026, AI will increase SOC efficiency by 40% compared with 2024 efficiency, beginning a shift in SOC expertise toward AI development, maintenance and protection.”
Why the SOC Needs an AI Analyst
As alert complexity rises, so does burnout and alert fatigue. SOC analysts today spend too much time sifting through noise and manually triaging alerts, rather than taking action to proactively secure the environment. According to the 2024 SANS Detection and Response Survey, more than half of security teams say false positives are a huge problem, and 62.5% are overwhelmed by sheer data volume.
A major reason for this frustration is that security teams are fighting with their own tools. In a recent State of Security 2025 report, Cisco’s Splunk surveyed over 2,000 security professionals in their community to find:
59% spend too much time and/or effort maintaining tools and associated workflows
51% admit their tools do not integrate well with one another
47% face alerting issues
32% of teams do not have the requisite skills to be efficient in the SOC
Tier-1 alert triage is overwhelming. Analysts face tens of thousands of Tier-1 alerts per day, and on average, security analysts are only getting to half of the alerts they’re supposed to review. Combined with these SOC inefficiencies, the volume becomes too high for human-only triage. As a result, detection and response times suffer. Gartner says, “AI agents are emerging as a critical solution to enhance efficiency, reduce burnout, and enable teams to focus on strategic initiatives.”
An AI SOC Analyst serves as an extension of SOC teams, automating incident response by interpreting natural language instructions in security runbooks to execute tasks such as alert triage, containment, and remediation actions. While an AI SOC Analyst autonomously handles over 90% of Tier-1 tasks, human analysts remain in control of critical decisions and can interface with the AI SOC Analyst using natural language for additional enrichment, investigation, and recommended next steps.
Socrates is Torq’s agentic AI SOC Analyst — a self-deterministic, autonomous AI Agent that plans, reasons, and acts the way a human SOC analyst would. Unlike SOAR solutions or common Generative AI chatbots, Socrates does not require human instruction or guidance. Socrates understands the SOC objectives and executes complex actions with minimal oversight.
Legacy SOAR and generic workflow automation solutions offer AI chatbots that run on static, rule-based playbooks — controlled by human input. And, while GenAI augments case triage by generating context to help reduce detection and response times, it is still largely reactive and reliant on human analysts to instruct, guide, and manually trigger remediation actions. Agentic AI, on the other hand, represents the next leap towards a more autonomous SOC.
According to IDC’s latest report, agentic AI has enormous potential in cybersecurity as it can process and solve problems the way a human being would. Socrates isn’t reactive — it’s adaptive. To continuously improve and evolve with new threats, Socrates uses:
Semantic memory to understand prompts and take explicit action
Episodic memory to learn from past incidents to develop new strategies
Procedural memory to make decisions on which tools to use and which data to gather
The Anatomy of Socrates: Torq’s OmniAgent
Socrates is more than just a single AI Agent. Socrates sits at the helm of Torq’s Multi-Agent System (MAS), acting as an OmniAgent in charge of coordinating multiple specialized AI Agents. Each of these agents is trained to perform a specific task, and is capable of using sophisticated iterative planning and reasoning to solve complex, multi-step problems autonomously. Torq’s AI Agents include:
Runbook Agent: Autonomously plans and adapts incident response runbooks with a deep knowledge and understanding of the environment.
Investigation Agent: Performs deep-dive investigations in seconds, uncovering hidden patterns across disparate data sources and tools to pinpoint root causes and assess threat impact.
Remediation Agent: Executes remediation actions, closing the loop with verifiable outcomes, either by autonomously following the associated runbook or through human-in-the-loop response.
Case Management Agent: Gathers real-time and historical data, organizes case timelines, highlights key indicators, and reprioritizes incidents based on evolving information.
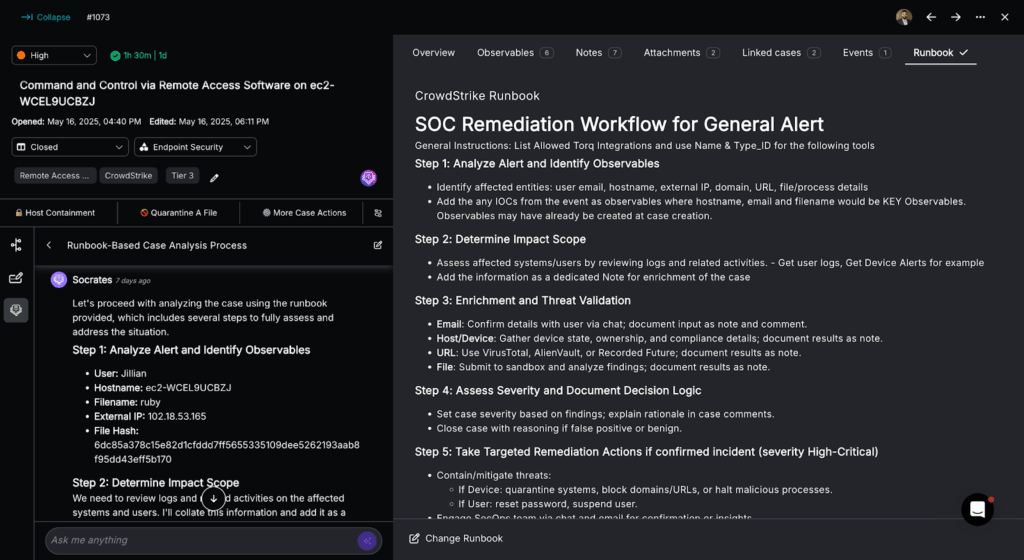
So, how does Socrates leverage Torq’s MAS to perform Tier-1 security tasks? Let’s look at this Command and Control attack detected by Crowdstrike and see how tasks previously handled by human analysts are now handled with unprecedented efficiency by Torq’s AI SOC Analyst, Socrates.
Watch Socrates, Torq’s AI SOC Analyst, following the guidelines in a SOC runbook to triage a case automatically.
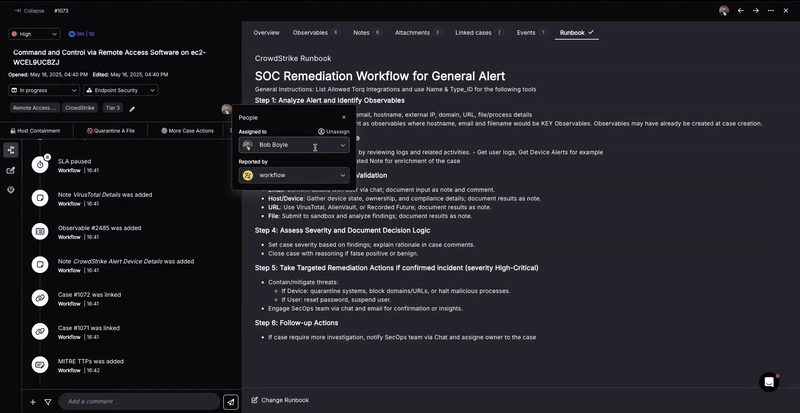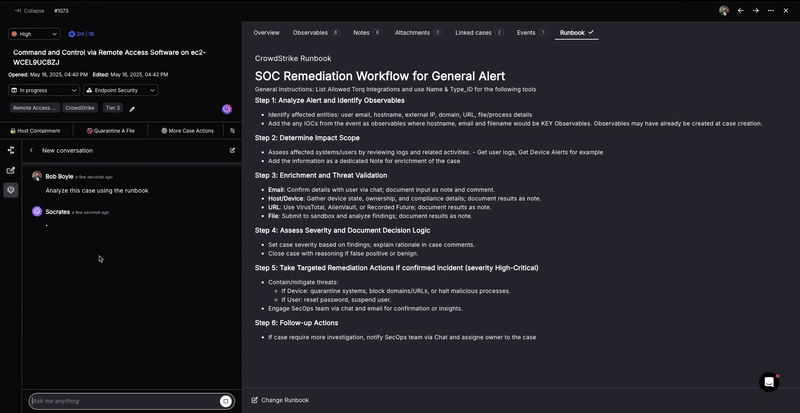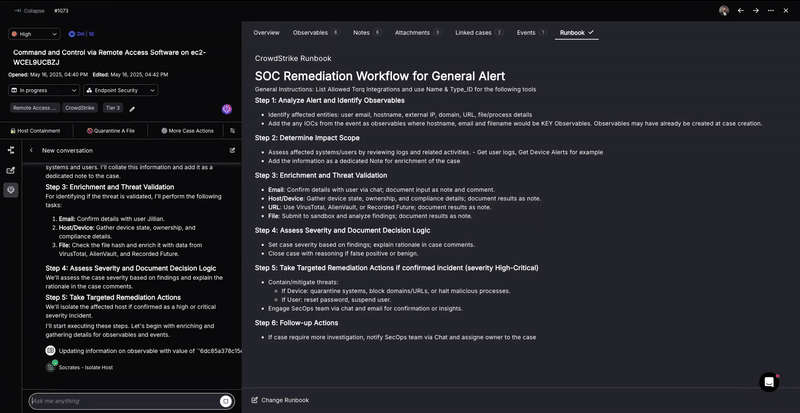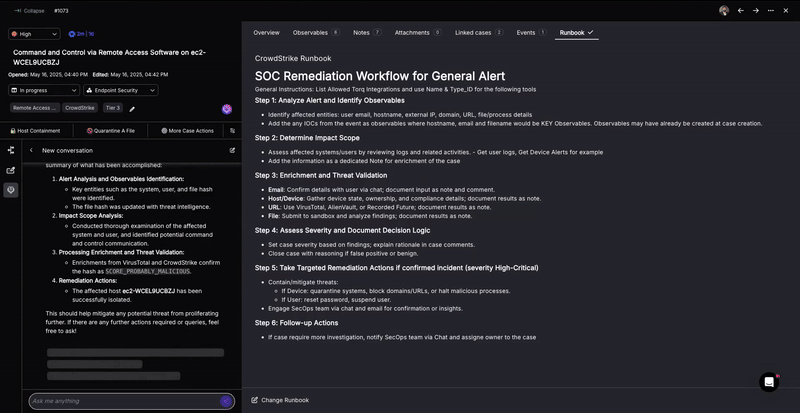
1. Automatic Runbook Analysis
When a security event arises, an analyst traditionally consults a “runbook” – a guide specifying the response to that specific type of event. Today, these “runbooks” exist in all modern SOCs and are prepared by senior architects to benefit Tier-1 and Tier-2 analysts.
Torq Socrates looks at outcomes of historical cases and associates the appropriate runbook based on the observables of the new case. Socrates automatically analyzes runbooks written in natural language, typically containing step-by-step procedures for handling various security incidents. By analyzing the semantic meaning of the natural language instructions, the AI SOC Analyst derives action flow from the recommended response strategies for different security events.
The associated case remediation runbook is written in natural language that Socrates analyzes, “understands,” and can follow.
2. Deep Research Incident Investigations
The many security tools available in the arsenal of Tier-1 SOC analysts can return a large amount of detailed information. The analyst’s goal is to synthesize this information into a decision about which next steps to take, according to the runbook’s guidance.
Just as human analysts rely on insights from the runbook, Socrates can assist in automating investigation or even incident response tasks. This includes executing tasks such as alert triage, data enrichment, containment, and remediation actions, which speeds up response times and reduces the manual effort required from human analysts.
An agentic AI SOC Analyst like Socrates excels at processing both structured and unstructured security tool data. This enables it to analyze complex information and create dynamic decision trees based on runbook analysis. These decision trees adapt to the specific context of each incident, allowing for more efficient and accurate incident handling. For example, Socrates can determine: Is the file malicious? Is the user a very important person (VIP)? Is the activity frequent or infrequent during a specific time period indicating anomalous behavior?
Socrates utilizing Crowdstrike, VirusTotal, and a deep understanding of the organization’s environment to query observables and distill the relevant information.
3. Knowledge of Security Frameworks for Context
More experienced alert triage specialists bring their own contextual knowledge and understanding of networking, endpoint architecture, and attack techniques into the mix.
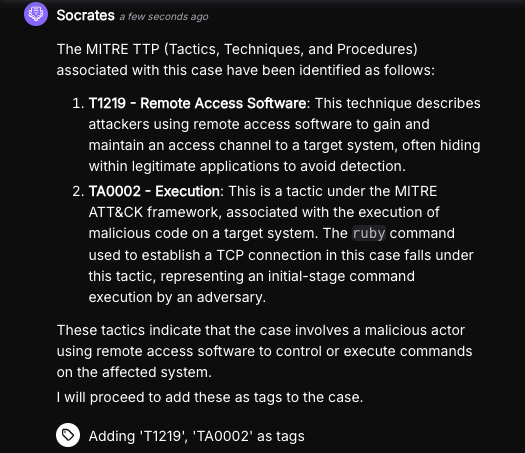
AI Agents are trained on an immense body of natural language documents containing information about the above and more. This allows the semantic analysis of an AI Agent to match the observed outcome of a security tool and the technique described in a documented framework, such as the MITRE ATT&CK framework.
Using the above technique, Torq’s agentic AI SOC Analyst, Socrates, leverages the information available in numerous documents describing attack frameworks, such as the MITRE ATT&CK framework, and maps its tactics and techniques to the outcomes observed in the analyzed security event.
Intelligent modeling with Torq’s AI SOC Analyst Socrates enables it to mimic a human-like thinking process, correlating information efficiently and mapping the appropriate outcomes to common frameworks like the MITRE ATT&CK framework, NIST, and more.
4. Leveraging Hyperautomation to Perform Designated Remediation Actions
The next step for a human analyst is to carry out the remediation actions outlined in the runbooks, choosing the proper tool and executing the instructions.
Based on the content of the runbook, the AI SOC Analyst utilizes its semantic analysis capabilities to suggest and trigger suitable Hyperautomated workflows and security tools from the list of ones explicitly made available within the Torq platform. These workflows align with the specific steps outlined in the document conveyed in natural language.
Torq Socrates performing the initial actions within the runbook.
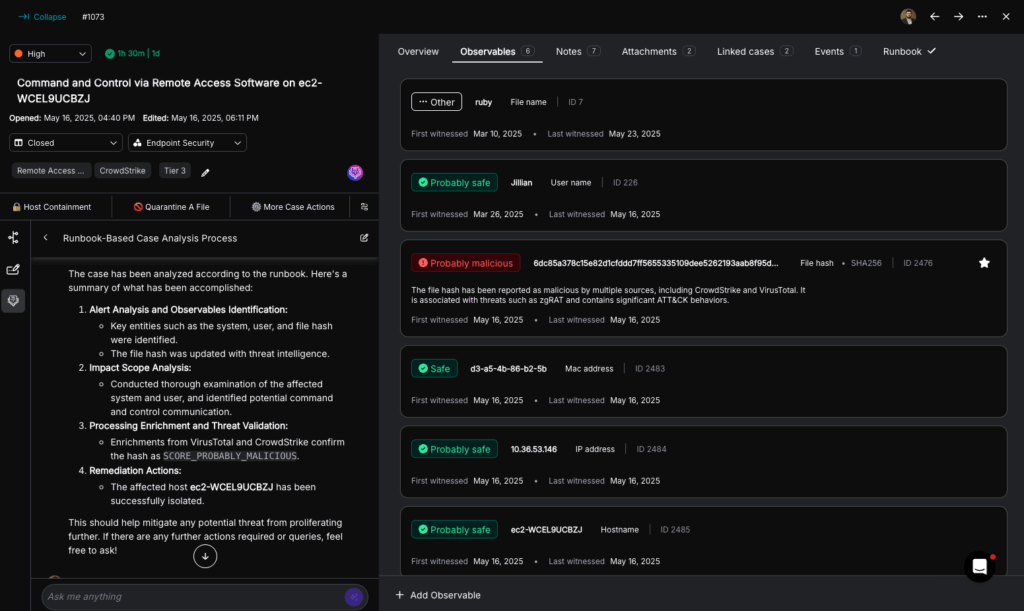
5. Intelligent Case Management and Documentation
An important pillar of any operational practice is the meticulous documentation of all actions taken, decisions, and achieved outcomes.
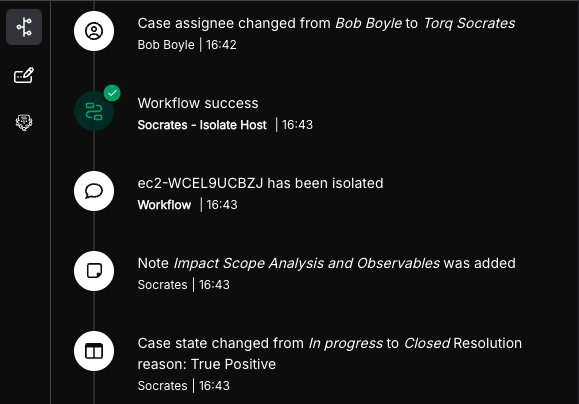
AI Agents have proven to be efficient at summarizing large amounts of natural language text. Torq Socrates leverages this capability to summarize the “conclusions” and desired next steps, and document them in the “case timeline”. Socrates then reaches back into its toolbox and ability to take action autonomously, marking the case as “closed” and moving the case forward without any human intervention.
Torq Socrates summarizing the findings and actions taken of the security event and automatically adding them to Torq’s built-in ticket management system timeline.
How Security Teams Use Socrates Today
Gartner forecasts that by 2028, multi-agent AI in threat detection and incident response will rise from 5% to 70%. For Torq customers leveraging Socrates, this is already their reality.
“I believe the successful use of Torq Agentic AI in SOC operations shows up in practical outcomes. With Torq Agentic AI, the answer is yes to questions such as: Are analysts happier? Are they sticking around? Do they have time to focus on more interesting and complex investigations? Are MTTM and MTTR lower? Torq Agentic AI extends and enhances our team so it can make better decisions more quickly — resulting in stronger security all around.”
Mick Leach, Field CISO, Abnormal Security
Socrates isn’t just another tool — it’s another teammate. And it’s changing the way security gets done. With Socrates, security decisions are made with context, fully automated incident response becomes the default, and agentic AI becomes the connective tissue across previously siloed security solutions that enable SOC teams to move from human-in-the-loop to human-on-the-loop.
According to IDC, Torq HyperSOC, powered by Socrates, helps:
Eliminate over 95% of Tier-1 analyst workload
Reduce time-to-remediation by 90%
Increase case handling capacity 3-5x with zero added headcount
Torq Socrates is designed to handle Tier-1 triage actions by mapping the tasks and activities of human Tier-1 analysts to use cases leveraging agentic AI. With Torq Socrates as their AI SOC Analyst, human security analysts remain in charge of processes and outcomes while introducing dramatic new efficiencies and incident response accuracy, alleviating security analysts’ most critical challenges.
Want to meet Socrates? Request a demo. And get the AI or Die Manifesto to learn strategic considerations and CISO advice for deploying AI in your SOC.
Cybersecurity is foundational to the survival and success of modern businesses. As digital operations expand, the risk of attacks, data breaches, and operational disruption increases dramatically, making cybersecurity not just important, but absolutely essential.
With digital transformation accelerating, remote and hybrid workplaces becoming the norm, and cyber threats evolving rapidly, organizations must adopt proactive cybersecurity strategies.
Traditional security measures alone no longer suffice — the speed and sophistication of modern threats demand cutting-edge solutions like Hyperautomation and agentic AI. Organizations today need automated and scalable cybersecurity technology.
Learn the latest cybersecurity best practices, how to implement them, and how Hyperautomation platforms like Torq ensure your defenses scale effortlessly.
What are Best Practices in Cybersecurity?
Cybersecurity best practices are proactive measures, policies, and technologies designed to minimize your organization’s cyber risk. Adhering to these practices helps businesses stay secure by preventing breaches, ensuring compliance, protecting sensitive data, preventing data breaches, and maintaining business continuity.
Many cybersecurity frameworks emphasize the “5 C’s of cybersecurity”:
Change: Regularly updating security measures.
Compliance: Adhering to industry standards and regulations.
Cost: Balancing security spending and effectiveness.
Continuity: Ensuring ongoing business operations after incidents.
Coverage: Comprehensive protection across all digital assets.
To improve cybersecurity, companies must combine extensive policies, employee education, strong access controls, and real-time threat response, ideally powered by scalable Hyperautomation platforms.
10 Essential Cybersecurity Best Practices (and How Torq Hyperautomates Them)
Cyber threats move fast, and your defenses need to move faster. These ten best practices are non-negotiable for modern SOC teams. But implementing them manually? That’s where most organizations fall behind.
Torq Hyperautomation™ eliminates the friction by turning best practices into fully automated, always-on workflows. Whether enforcing access controls, responding to phishing attempts, or monitoring endpoints, Torq ensures each control is executed precisely and at scale.
Here’s what to put in place now — and how Torq helps you do it effortlessly.
1. Use Strong, Unique Passwords and a Password Manager
Passwords are often the first — and weakest — line of defense against cyber intrusions. Weak or reused passwords significantly increase the risk of account compromise, especially in credential stuffing and brute-force cyber attacks. Organizations should enforce strong password policies that mandate the use of long, complex, and unique passwords for every account.
To ease the burden on employees, deploy enterprise-grade password managers that generate, store, and autofill passwords securely. These tools reduce password fatigue and help prevent risky practices like writing down credentials or reusing them across platforms. Periodic password audits can also be automated with Torq, which can trigger alerts when passwords aren’t updated or don’t meet compliance standards.
MFA is one of the simplest and most effective ways to prevent unauthorized access. It ensures that even if credentials are compromised, hackers can’t easily access sensitive systems without a second form of verification, such as biometrics, hardware tokens, or authenticator apps.
Torq enhances MFA implementation with Role-Based Access Control (RBAC) automation workflows. Security teams can use Torq to enforce MFA across platforms, audit authentication events, and automatically revoke access for users who haven’t completed MFA setup, minimizing friction and oversight.
3. Keep All Software and OS Up to Date
Outdated systems often harbor unpatched vulnerabilities that threat actors exploit. From zero-day vulnerabilities in operating systems to neglected third-party apps, every unpatched asset is a liability.
Implement an automated patch management strategy. With Torq, security teams can set up workflows that monitor software versions across endpoints, flag outdated components, and trigger notifications or remediation actions when updates are overdue. Coupling this with scheduled audits ensures continuous hygiene and reduces attack surfaces.
4. Install Antivirus and Anti-Malware on Every Device
Endpoint protection remains critical in defending against a broad range of cyber threats including ransomware, malware, and trojans. Organizations should deploy endpoint detection and response (EDR) solutions that use real-time behavioral analysis, not just signature-based detection.
To ensure these tools stay effective, Torq can integrate with antivirus platforms to monitor endpoint health, validate update statuses, and automate quarantine or isolation actions in response to detected threats, speeding up remediation and reducing exposure windows.
5. Secure Networks with Firewalls and VPNs
Firewalls and VPNs help shield organizational networks from unauthorized access and malicious traffic. Firewalls block suspicious inbound/outbound traffic, while VPNs provide encrypted tunnels for secure remote access, especially critical in hybrid work environments.
Torq can enhance these protections by automating firewall rule updates, triggering alerts when unexpected changes occur, and monitoring VPN usage for anomalous patterns such as logins from unusual geolocations or times. This automation ensures your network security posture stays strong without requiring constant manual oversight.
6. Regularly Back Up Data to the Cloud and Offline
Cyberattacks like ransomware and accidental deletions can lead to devastating data loss. Regular backups are your safety net. Organizations should adopt a 3-2-1 backup strategy: three copies of data, two on different media, and one offsite.
Torq helps ensure backup best practices are followed by automating backup verification, alerting if a backup fails, and orchestrating regular backup operations. Teams can also use Torq to conduct post-backup security posture checks to ensure backups aren’t infected or misconfigured, ensuring they’re both usable and secure.
7. Educate and Train Employees on Phishing and Social Engineering
The human element remains the weakest link in cybersecurity. Regular security awareness training, including simulated phishing campaigns, is essential to prepare employees for common social engineering tactics.
Torq supports these efforts with automated phishing response workflows. When phishing attacks are reported or detected, Socrates, our AI SOC Analyst, rapidly investigates, auto-remediates the message, and updates the reporting employee, reducing response time and enabling analysts to focus on complex threats. Combined with training, this creates a layered defense against email-based attacks.
8. Use Encryption for Sensitive Data at Rest and in Transit
Encryption ensures that even if data is intercepted or accessed without authorization, it remains unreadable. All sensitive data — customer records, financial information, proprietary code — should be encrypted both at rest (on storage systems) and in transit (during transmission over networks).
Organizations should enforce the use of industry-standard protocols such as AES-256 and TLS 1.3, and regularly audit encryption configurations. Torq can automate policy enforcement and integrate with encryption management systems to verify encryption coverage and trigger alerts for unprotected data assets.
9. Limit User Access with RBAC and Least Privilege
The principle of least privilege (PoLP) limits access rights for users to the bare minimum necessary. Overprivileged accounts are a goldmine for cybercriminals and a major source of internal risk.
Torq’s RBAC capabilities automate access provisioning, ensure only necessary permissions are granted, and continuously audit user roles. If access privileges drift over time due to role changes or misconfigurations, Torq can automatically flag or correct them, helping prevent lateral movement in case of compromise.
10. Monitor for Suspicious Behavior and Automate Alerts
Traditional alerting often leads to analyst burnout due to high volumes of low-fidelity alerts. Modern threats demand intelligent monitoring that can identify anomalies and respond in real time.
Torq’s multi-agent system continuously monitors systems for signs of compromise and suspicious behavior. When an anomaly is detected, it automatically triages the event, enriches it with context, and initiates workflows to investigate or contain the threat, without requiring human intervention. This reduces MTTD and MTTR, keeping your defenses agile and proactive.
Common Cyber Threats Every Organization Faces
To understand why these security best practices matter, consider some of today’s most pressing cyber threats:
Ransomware: Ransomware attacks encrypt critical data, demanding payment for restoration. Organizations must maintain backups, enforce patch management, and automate threat detection to prevent such attacks.
Phishing: Attackers trick employees into revealing credentials or downloading malware. Continuous security awareness training and automated phishing remediation significantly reduce phishing-related breaches.
Insider Threats: Whether intentional or accidental, insider threats pose significant risk. Implement strong RBAC policies and continuous user activity monitoring to quickly detect suspicious behavior.
DDoS (Distributed Denial of Service): Attackers overwhelm your network or services with traffic, disrupting operations. Deploy firewall protections, traffic monitoring, and automated mitigation responses to maintain availability.
Hyperautomate Your Cybersecurity Best Practices with Torq Hyperautomation
Even the most extensive cybersecurity best practices can fall short without consistency, speed, and scalability. That’s where Torq Hyperautomation steps in.
Torq automates every layer of your security operations — from detection to remediation — without writing a single line of code. Whether you’re enforcing MFA, orchestrating real-time phishing response, or managing RBAC policies across hybrid environments, Torq executes it all with precision and speed.
Torq’s Hyperautomation platform empowers organizations to convert cybersecurity best practices into always-on, fully orchestrated workflows. Our agentic AI capabilities, including our multi-agent system led by Socrates, detect, triage, and respond to alerts instantly, without flooding your team with noise.
This means your security analysts spend less time on repetitive triage and more time focused on high-impact, strategic initiatives. And with a vast library of integrations and workflow templates, you can implement sophisticated security controls faster than ever.
Build a Stronger, Smarter Security Posture
Cybersecurity threats are growing rapidly, but so are the solutions to fight them. Adopting these cybersecurity best practices will strengthen your organization’s defenses against modern threats. However, manually managing every aspect of security is unsustainable.
Torq Hyperautomation gives your organization an edge by transforming security best practices into streamlined, automated operations. From employee training and endpoint protection to real-time threat response and compliance reporting, Torq ensures that your security posture isn’t just strong; it’s intelligent, adaptable, and future-ready.
Ready to strengthen your cybersecurity posture with Torq?
Security teams face mounting pressure to defend against sophisticated cyber threats. Traditional automation strategies are often rigid, reactive, and lack the ability to scale effectively. Many SOCs already have access to generative AI to assist with simple tasks and now Torq has brought agentic AI into the mix — which thinks, acts, and learns autonomously to handle security risks. What’s next?
A multi-agent system (MAS) represents the next era for SecOps: specialized AI agents that work together to solve problems. Each AI agent has a specific role that it is responsible for executing, and together, this system of agents collaborates to achieve a common goal.
Let’s explore what a multi-agent system is, why it’s essential for SecOps, and how Torq leverages multi-agent AI to redefine security operations.
What Is a Multi-Agent System?
A multi-agent system is a network of artificially intelligent software agents working collaboratively to achieve complex, multi-step goals, often orchestrated by an OmniAgent, or “Super Agent”.Unlike monolithic automation tools, each agent within the system operates autonomously, specializing in specific tasks and communicating seamlessly to coordinate actions.
Multi-agent systems comprise three key components: the individual AI agents themselves, a communication framework, and a control structure that governs how agents interact. These smaller, focused agents that perform specific tasks break down complex security operations into manageable pieces.
Multi-Agent System Defined
A multi-agent system (MAS) is a team of independent AI agents that work collaboratively to complete multi-step tasks or solve complex problems. Each agent in a MAS operates autonomously, specializes in a specific function, and communicates with other agents to coordinate actions, often orchestrated by an OmniAgent or “Super Agent.”
Unlike traditional automation, which follows rigid, sequential processes, multi-agent AI systems enable parallel task execution, dynamic adaptation, and intelligent decision-making. In SecOps, MAS technology enables teams to scale, automate, and respond to threats significantly faster and more efficiently.
Why Multi-Agent AI Outperforms Single AI Agents
Scalable: A MAS enables multiple agents to work simultaneously across tasks — unlike traditional automation that handles events sequentially. This parallel approach dramatically increases operational speed and resilience.
Specialization: Rather than relying on broad workflows, multi-agent AI deploys specialized agents that are experts in their roles. This ensures every security incident receives expert-level attention explicitly tailored to its context.
Collaborative Learning: Multi-agent systems leverage AI reasoning to improve continuously. They learn from incidents, adapt to changing threats, and refine their workflows automatically, enabling ongoing evolution and enhanced security posture.
Cost Savings: By breaking down responsibilities into smaller specialized tasks, the workload and resource consumption of the AI system is more efficiently distributed, resulting in a less costly AI implementation. Rather than a single general-purpose AI chatbot working step by step through a problem, the parallel execution of bite-sized tasks helps save the SOC money in the long run.
How Do Multi-Agent AI Systems Work in the SOC?
In a MAS, each agent operates independently, making its own decisions based on its specific role, environment inputs, and communication with other agents.
Here’s how a typical multi-agent system operates:
Autonomy: Each agent can act independently without needing centralized control.
Specialization: Agents are assigned specific functions (e.g. triage, investigation, remediation, etc.) based on their unique capabilities and expertise.
Communication and coordination: Agents share information, either directly or through a central, orchestrating OmniAgent, to align activities, correlate relevant data, and avoid conflicts.
Parallel execution: Multiple agents work simultaneously, dramatically accelerating task completion compared to linear automation models.
Adaptability: Agents dynamically adjust their behavior in response to real-time inputs, changes in the threat landscape, or evolving priorities.
Emergent behavior: Through collaboration, the system can achieve more sophisticated outcomes than any single agent.
Multi-Agent System Use Cases In the SOC
Alert Triage at Scale
With a Multi-Agent System, autonomous agents can instantly evaluate thousands of incoming alerts, enrich them with context, and determine severity using internal telemetry and threat intel sources. Instead of drowning analysts in false positives, MAS filters out noise and flags what actually matters. This dramatically reduces Mean Time to Remediate (MTTR) and frees up security teams to focus on high-value investigations.
Runbook Orchestration
Building and maintaining runbooks shouldn’t require a dev team. Multi-agent systems enable no-code orchestration of complex workflows that span cloud platforms, identity providers, SIEMs, EDRs, and more. Security teams can define desired outcomes in natural language, and AI agents translate those into structured, executable playbooks. This accelerates time-to-value, eliminates human error, and ensures consistent, repeatable outcomes without code dependencies.
Incident Response
A Multi-Agent System coordinates the investigation, containment, remediation, and closure of a case as a single, seamless operation. Each agent specializes in a specific role for triage, root cause analysis, identity verification, and remediation, working in parallel under the direction of an OmniAgent. Threats are resolved faster, response is consistent, and your SOC operates like a finely-tuned machine.
Threat Hunting
Proactive threat-hunting agents continuously monitor activity across your environment, looking for behavioral anomalies, pattern deviations, or signals buried in noise. These agents correlate telemetry from endpoints, cloud assets, and user behavior to surface suspicious activity. They initiate investigations automatically, escalating only when human insight is required.
The World’s First Multi-Agent System for The SOC
Torq is the first cybersecurity platform to launch a true Multi-Agent System (MAS) purpose-built for the SOC. Torq HyperSOC™’s MAS architecture deploys a team of specialized, autonomous AI Agents, coordinated by Socrates, our OmniAgent, to execute complex SecOps workflows in parallel, at scale, and without human intervention. Meet Torq’s AI Agents.
Socrates, the AI SOC Analyst
Socrates is the OmniAgent mastermind that serves as the command center for all other agents. It interprets high-level goals and directives and then orchestrates the appropriate sequence of AI Agents to execute the task with precision. Socrates understands natural language, so human SOC analysts can kick off complex investigations or remediation plans with simple prompts. It turns strategic intent into scalable, autonomous action.
Runbook Agent
The Runbook Agent is the architect of execution. It takes strategic objectives, like responding to phishing, escalating ransomware alerts, or handling IAM requests, and maps them to dynamic, modular workflows. This agent builds the execution plan, delegates tasks to specialized agents, and ensures every step adheres to security policy and best practices. It enables your SOC to execute with precision, speed, and zero guesswork.
Investigation Agent
When context is critical, the Investigation Agent takes over. It digs deep into alert data, pulling from internal logs, threat intelligence platforms, CMDBs, and identity systems to uncover the root cause of a threat. It correlates signals, identifies attack paths, and enriches cases with detailed findings. This agent handles the heavy lifting, allowing human analysts to focus on informed decision-making.
Remediation Agent
Once a threat is validated, the Remediationgent initiates the full response lifecycle, from isolating endpoints and revoking credentials to updating firewall rules and notifying affected users. It acts decisively and autonomously to contain incidents and restore normal operations without waiting for human intervention.
Case Management Agent
The Case Management Agent automatically compiles case summaries, prioritizes incidents based on business impact and severity, and routes alerts to the right stakeholders. It also captures analyst actions and decisions to maintain clean audit trails and feed the system’s memory for more intelligent responses over time. This agent transforms raw alerts into structured, actionable intelligence.
In Torq HyperSOC™,, each AI Agent specializes in a core security function — and together, they operate as an intelligent, coordinated, tireless SOC workforce. This collaborative multi-agent AI architecture eliminates bottlenecks, accelerates response, and drives precision at scale, transforming reactive SOCs into proactive, autonomous security operations.
The Future of SecOps: The Autonomous SOC Powered by Multi-Agent AI
The security industry has outgrown one-size-fits-all automation. Torq’s Multi-Agent System offers a new path forward: agentic AI that works in tandem, orchestrated by Socrates, to transform your SOC from reactive to autonomous. But Torq’s latest advancements truly push our MAS into next-gen territory.
Retrieval-augmented generation (RAG) enhances Torq’s MAS by giving our AI Agents access to private and external knowledge bases. That means every decision is made with the most current, relevant intelligence. RAG enhances everything from case enrichment and threat correlation to report generation, enabling smarter, faster response without sacrificing accuracy.
Model-Context Protocol (MCP) is another Torq game-changer. Torq is the first autonomous SOC platform to natively support MCP, which guarantees AI decisions are grounded in the exact context of your environment. This ensures precise, verifiable actions based on your organization’s specific infrastructure, data, and threat landscape.
Together, these advancements bring Torq’s vision to life: a truly autonomous SOC where AI handles the heavy lifting and humans stay in control as strategic decision-makers.
See the world’s first true Multi-Agent System for the SOC in action.
Your SOC exists for one core reason: to rapidly reduce the mean time to detect, investigate, and respond to threats. The more efficiently your team operates, the faster you reduce essential KPIs like MTTR, MTTD, MTTI, and what we call ‘MTTx’ (mean time to anything).
Talking about efficiency is easy. Actually achieving it, especially when your SOC is drowning in alerts and your analysts are burning out, is another story entirely.
Reducing MTTR is a top priority for SOCs, yet many struggle to make meaningful progress. The root of the problem lies in legacy SOC environments’ outdated, manual, and disconnected nature.
If you’ve spent time in a SOC, these pain points are familiar:
Manual investigations slow everything down: Over half of security teams struggle with false positives and data overload. Analysts spend valuable time pivoting between tools, manually gathering context from logs, threat intel feeds, and asset databases. This “swivel-chair” approach introduces friction at every stage of the investigation.
Siloed tools don’t talk to each other: Most SOCs operate across dozens of disconnected platforms — EDR, SIEM, IAM, CMDB, ticketing, and more — without unified visibility or shared context. This makes correlating events and making informed decisions harder and slower.
High alert volume leads to fatigue: Teams receive thousands of alerts daily, many of which are false positives. Sifting through the noise to find true threats overwhelms even the most seasoned analysts, increasing the time it takes to detect and resolve incidents.
Disjointed shift handoffs cause delays: Without standardized processes or automated case management, investigations are often paused or reset between analyst shifts. Critical details get lost, increasing downtime and dragging out resolution timelines.
Inconsistent processes and tribal knowledge: The lack of documented workflows and reliance on individual expertise mean response varies from one analyst to the next. This inconsistency increases mean time to detect (MTTD), mean time to investigate (MTTI), and ultimately mean time to resolve (MTTR).
Delayed escalation and decision-making: Analysts often wait for senior approval before containing threats, primarily when procedures aren’t codified. This slows the response and allows attackers to move laterally or escalate privileges.
These pain points slow your team’s reaction times and increase risk. But these barriers disappear when Hyperautomation, AI, and smart case management are unified.
Why Reducing MTTR Is the Key to SOC Efficiency
What is MTTR in Cybersecurity?
MTTR (Mean Time to Resolution) measures the average time it takes to detect, investigate, contain, and fully resolve a security incident — from when it’s identified to when it’s no longer a threat. It’s one of the most critical KPIs for security operations because it directly reflects how quickly a SOC can respond to threats and minimize damage.
Related metrics include:
MTTD (Mean Time to Detect): How long it takes to identify that an incident has occurred.
MTTI (Mean Time to Investigate): The time required to assess and understand the scope and severity of an incident.
MTTR (Mean Time to Resolution): The full incident lifecycle — detection through response and resolution.
MTTx: A flexible term for any “mean time to X” metric, such as mean time to contain, recover, or respond.
High MTTR leads to longer dwell times, greater risk exposure, and higher operational costs. Reducing MTTR means:
Stopping attackers before lateral movement or data exfiltration
Limiting downtime and business disruption
Giving analysts time back to focus on proactive defense
Reducing MTTR is a direct path to stronger security, happier analysts, and a more efficient SOC.
How AI, Hyperautomation, and Case Management Can Reduce MTTR
Torq HyperSOC is an autonomous, cloud-native security operations platform designed to reduce MTTR by eliminating manual bottlenecks across the incident lifecycle. Built on the Torq Hyperautomation platform, HyperSOC combines:
Agentic AI (Socrates) to autonomously triage, investigate, and resolve threats
No-code/low-code orchestration for rapid integration with existing tools across SIEM, EDR, IAM, and SaaS environments
Natural language processing (NLP)-powered automation for dynamic workflows, smart case management, and intuitive analyst interaction
How Automation Speeds Detection, Investigation, and Response
Every minute matters in security. HyperSOC uses automation to minimize time spent on repetitive and manual tasks, which directly reduces MTTR.
Automated threat detection eliminates wait time for analyst triage.
Instant data correlation reduces downtime spent stitching logs, alerts, and asset context.
Hands-free auto-remediationtriggers the correct response playbooks based on the threat type.Audit-ready documentation is generated in real time, ensuring compliance and traceability.
Use Case #1: Neutralize a Reverse Shell Command & Control (C2) Attack
This example shows how Torq HyperSOC reduced MTTR from hours to under two minutes by automating detection, investigation, and containment, without human intervention.
Threat detection and autonomous response: When a Ruby-powered reverse shell (courtesy of njRAT) targeted an EC2 Linux instance, Socrates got to work. As Torq’s AI SOC Analyst, Socrates detected anomalous process behaviors and network connections, flagging the reverse shell command within seconds.
Real-time enrichment: Without waiting for analyst input, Socrates quarantined the EC2 host. The platform harvested file hashes, process trees, and destination IPs, then enriched them via threat intel feeds and internal CMDB lookups.
AI-generated reporting: Through a deep understanding of the environment and analysis of the remediation runbook associated with the detected use case, Socrates autonomously killed the malicious process in its tracks before the bad actor was able to spread laterally, exfiltrate sensitive data, or cause any further damage. In under two minutes, the HyperSOC dashboard included an AI-generated incident report with prioritized next steps and detailed documentation of every AI-driven action taken.
Result: The threat was detected and neutralized without manual intervention, reducing MTTR and allowing analysts to move on to higher-priority tasks.
Torq HyperSOC™ detected and neutralized a Ruby-based njRAT attack on an EC2 Linux instance in under two minutes.
Use Case #2: Reduce MTTR with Automated MITRE ATT&CK Tagging
Manually identifying and tagging MITRE ATT&CK tactics, techniques, and procedures is time-consuming.
Automatic TTP mapping: Socrates can streamline this process by automatically linking and tagging threats with relevant MITRE ATT&CK tactics, techniques, and procedures (TTPs).
Runbook recommendations: The AI Agent parses case data, file hashes, process names, network connections, and behavior patterns, and distills them into discrete observables. Socrates cross-references each observable against the latest MITRE ATT&CK framework — pinpointing the primary tactic and related sub-techniques and procedures. For each matched TTP, Socrates auto-tags the case, links to relevant playbooks, and correlates with past incidents that used the same methods.
Automated scoring: Finally, the AI generates a concise report section that shows:
Tactic: TA0011 – Command and Control
Technique: T1219 – Remote Access Software
Procedure: njRAT reverse shell delivered via Ruby script on EC2 instance.
Confidence: 92%
Potential Impact: Successful execution of these TTPs can lead to unauthorized access and control of critical systems, leading to data breaches or disruptions.
Next Steps: Trigger the containment playbook, notify the Tier-2 SOC analyst team, and run a full asset sweep.
Result: Analysts no longer spend time manually tagging or correlating cases, which helps reduce MTTR and increase consistency across investigations.
Socrates auto-tagged MITRE ATT&CK TTPs for a reverse shell incident, cutting MTTR and surfacing next steps in seconds.
Use Case #3: Investigate and Close an Impossible Travel Alert in Minutes
Use Case #3: Investigate and Close an Impossible Travel Alert in Minutes
This case shows how Socrates cut MTTR from 20+ minutes to under three, replacing a manual investigation across multiple tools with a fully automated workflow.
Cross-platform checks: Okta flagged suspicious logins from Austria, Singapore, and Brazil for a single user within a 30-minute window, an impossible travel scenario indicating potential compromise.
Anomaly resolution: Socrates autonomously checked the user’s leave status in Workday and calendar systems. Next, Socrates messaged the employee on Slack, capturing their response directly into the case notes. Simultaneously, it enriched each login IP against external threat intelligence feeds, scoring them for risk and historical malicious activity.
Automated case closure: Socrates then compared the session details against the user’s normal behavior baseline to spot anomalies. Finally, because the user had confirmed the unusual travel and all IP reputations returned legitimate, Socrates marked the alert as a benign true positive, documented the reasoning, and closed the case.
Result: MTTR was reduced to three minutes, false positives were resolved autonomously, and analysts stayed focused on real threats.
Socrates investigated suspicious Okta logins, cross-checked HR systems, messaged the user, and closed the alert autonomously.
What These Results Mean for Your SOC
The use cases above aren’t isolated wins — they represent a repeatable, scalable model for transforming your security operations. When you reduce MTTR through AI, Hyperautomation, and intelligent case management, your SOC becomes faster, more resilient, and dramatically more cost-effective.
Proving the ROI of MTTR Reduction
Reducing mean time to resolution doesn’t just make your SOC more efficient — it delivers measurable business value:
Faster resolution = less dwell time and downtime: The longer a threat lingers, the more damage it can do. By shortening the incident lifecycle, your team minimizes business disruption, data loss, and risk exposure.
Fewer escalations = less analyst fatigue: Automating repetitive tasks and low-risk decisions reduces the volume of escalations sent to senior analysts. That frees them up to focus on high-value investigations — and helps reduce burnout.
Higher accuracy = better threat outcomes: With real-time enrichment, contextual tagging, and autonomous decision-making, your SOC can respond more precisely, even under pressure. This leads to faster containment, fewer false positives, and stronger compliance reporting.
Operational resilience = higher ROI: SOCs that reduce MTTR gain more value from their existing tools and staff. You’re not just solving problems faster — you’re using fewer resources.
How to Start Automating Your SOC the Right Way
To reduce MTTR, you don’t need to rip and replace your entire tech stack. The best approach is incremental and targeted, focusing first on areas with high volume, low complexity, and high analyst fatigue.
Start by automating:
High-volume alert triage: Automatically enrich, correlate, and suppress low-risk alerts based on historical context and threat intelligence.
Repetitive enrichment tasks: Automated gathering of user context, asset data, geolocation, IP reputation, and vulnerability information can be done in seconds, not hours.
Access investigations and policy violations: Build workflows that verify unusual access events across IAM, HR, calendar, and communication platforms, then take action based on policy.
These aren’t theoretical benefits; they’re proof points from the frontlines of modern AI-powered SOCs. When the powers of Hyperautomation, AI, and intelligent case management are combined in Torq HyperSOC, your team moves smarter and faster.
Instead of being bogged down, analysts are empowered to lead, strategize, and scale across complex environments. That’s how you reduce risk, retain talent, and prove real value.
Want to see HyperSOC in action? Book a demo now — and don’t miss our Field CISO’s guide full of practical advice for building a more efficient SOC.
Threat intelligence is the cornerstone of proactive security. By collecting and analyzing indicators of compromise (IOCs), tactics, techniques, and procedures (TTPs), and adversary infrastructure, threat intelligence tools help cybersecurity teams spot attacks before they escalate.
But here’s the catch: Most tools stop at surfacing raw intel. They hand you the data but don’t help you operationalize it. This results in analysts drowning in noise, alert fatigue, and slow incident response times.
Explore the top categories of threat intelligence tools and see how Torq Hyperautomation bridges the gap between intel and action, delivering real-time enrichment and autonomous response at scale.
What Are Threat Intelligence Tools?
Threat Intelligence (TI) tools are software and services that collect, enrich, analyze, and distribute information about cyber threats so security teams can detect, prioritize, and respond faster.
What Threat Intelligence Tools Do
Collect data: Ingests signals from OSINT, dark web sources, malware sandboxes, DNS/WHOIS, product telemetry, ISACs, and commercial vendor feeds to build a comprehensive threat picture.
Normalize and enrich: Standardizes formats, deduplicates indicators, and adds context — actor, campaign, TTPs, confidence, and sightings — so data is usable and trustworthy.
Correlate and score: Links indicators to behaviors using frameworks like MITRE ATT&CK and assign risk and confidence to drive prioritization.
Distribute intel: Pushes curated intelligence to SIEM, EDR, or SOAR via APIs and STIX/TAXII, often triggering automated playbooks.
Search and investigate: Lets analysts pivot across IPs, domains, and hashes, build campaign timelines, and track adversary infrastructure.
Report and measure: Provides dashboards, alerts, and takedown and mitigation guidance while tracking coverage and efficacy.
Threat Intelligence Tooling Categories
Feeds (Raw indicators): Continuous streams of IPs, domains, hashes, phishing kits, and C2 infrastructure.
Threat Intelligence Platforms (TIPs): Central hubs that aggregate sources, dedupe and score indicators, enable sharing, and orchestrate automation.
Vertical/Community intel: ISAC/ISAO groups that facilitate trusted, sector-specific sharing of timely threats and mitigations.
Managed TI services: Provider-run offerings where human analysts deliver curated, finished intelligence and advisory support.
4 Types of Threat Intelligence
Strategic (Board/CISO): High-level trends, risks, and business impact to inform investment and policy.
Operational (SOC/IR): Campaign-level insights — adversaries, infrastructure, and TTPs — translated into detections and response actions.
Tactical (Detections): Short-lived IOCs with confidence and expiry to feed blocklists and detection rules.
Technical (Artifacts): Low-level signatures and artifacts — YARA/Sigma rules, decoders, and malware I/O — used to research and codify detections.
While threat intelligence is vital for shifting from reactive to proactive security, most tools stop short of execution. They provide intel but don’t automate triage or incident response, leaving a critical gap in the security kill chain.
Why Threat Intelligence Alone Isn’t Enough
“Threat intelligence — while abundant — is frequently underutilized due to inconsistent application and a lack of objective analysis, keeping teams stuck in reactive mode.”
High-quality threat intelligence is essential for modern security operations, but even the best intel feeds can only take you so far. Many SOC teams still struggle to operationalize that intelligence effectively, facing challenges such as:
Siloed data sources: Threat intel often lives in separate tools and feeds, requiring analysts to manually pivot between consoles to correlate indicators with events in their environment. This not only slows investigations but also risks missing connections entirely.
Alert fatigue from unverified IOCs: Raw intelligence feeds can produce an overwhelming volume of indicators of compromise (IOCs). Without automated context and verification, analysts are forced to triage a flood of alerts, many of which turn out to be irrelevant or false positives.
Slow MTTR due to manual processes: Even when malicious activity is identified, enrichment, prioritization, and incident response often rely on a series of manual steps. This delays containment, gives adversaries more time to act, and increases the likelihood of impact.
The missing link is security Hyperautomation: The ability to take incoming threat intelligence and enrich it in real time, validate it against your environment, prioritize based on risk, and execute the right response automatically.
With Hyperautomation in place, security teams can:
Instantly correlate threat intel with live telemetry from SIEM, EDR, IAM, and cloud security tools.
Automatically filter out low-confidenceor irrelevant IOCs before they reach analysts.
Trigger pre-approved auto-remediation workflows such as blocking a domain, isolating an endpoint, or disabling a compromised account in seconds.
Threat intelligence is powerful, but it becomes truly operational when paired with automation. That’s how teams turn static data into actionable, measurable defense at machine speed.
The Power of Automated Alert Enrichment
Threat intelligence enrichment is the critical bridge between raw threat data and meaningful, actionable threat intelligence. It transforms a bare IOC or alert into a fully contextualized security event, giving analysts the information they need to make faster, more confident decisions.
Without enrichment, a malicious IP alert is just a red flag without a story. You know something might be wrong, but you don’t know:
Who controls the IP
When it was first reported as malicious
Whether it has been active in other attacks
If it’s currently interacting with your environment
With threat enrichment, those questions are answered instantly. You can see ownership, reputation scores, historical abuse records, and whether the threat currently targets your assets. This drastically reduces false positives, helps prioritize real threats, and accelerates triage, especially in high-volume SOC environments.
Real-Time Enrichment with Torq
Torq automates this process end-to-end, ingesting IOCs from virtually any source:
Open-source feeds like AbuseIPDB or AlienVault OTX
Commercial CTI platforms such as Recorded Future or CrowdStrike Falcon Intelligence
Internal telemetry from SIEM, EDR, IAM, and CSPM systems
Once ingested, Torq automatically enriches each IOC or alert with:
Threat intelligence lookups for risk scoring and category classification
WHOIS data to identify domain or IP ownership
GeoIP mapping for geographic attribution
Historical incident correlation to see if this IOC has appeared in past investigations
Enrichment is all about enabling faster, more precise action. With Torq, once an alert is enriched, it can immediately trigger targeted, pre-approved response runbooks, such as:
Block malicious IPs or domains at the firewall or secure web gateway
Disable compromised accounts in IAM systems like Okta or Azure AD
Quarantine infected endpoints via EDR tools like CrowdStrike or SentinelOne
Notify analysts in Slack or Microsoft Teams with full, structured context for review
Because enrichment and incident response are linked in the same Hyperautomation workflow, there’s no waiting for an analyst to manually look up data before taking action — vulnerabilities are validated, prioritized, and remediated in near real time.
Real-World Use Cases: How Torq Elevates Your Threat Intelligence Stack
IOC-Triggered Triage
Scenario: A new malicious IP is published by Abuse.ch’s SSL Blacklist feed.
How Torq Handles It:
The IOC enters Torq through a scheduled or webhook-based integration with Abuse.ch.
Torq automatically enriches it with:
Recorded Future for risk scoring and threat actor attribution.
VirusTotal for file and domain associations.
WHOIS and GeoIP for ownership and location details.
The enriched IOC is compared against SIEM and EDR telemetry to see if it’s active in your environment.
Based on the risk score and internal matches, Torq either:
Auto-blocks the IP in your firewall and secure web gateway.
Escalates the IOC to a case in Torq for analyst review.
Result: Threats are validated and acted on within seconds, without manual lookups or context switching.
Autonomous Response to High-Risk Alerts
Scenario: Correlated threat intel and internal detections reveal an active phishing campaign targeting corporate users.
How Torq Handles It:
The IOC feed from a commercial CTI provider flags multiple domains tied to a phishing kit.
Torq cross-references internal email gateway logs to confirm delivery attempts to specific users.
Upon confirmation, Torq executes automated actions:
Revokes credentials in Okta or Azure AD for targeted accounts.
Sends a Slack or Teams alert to affected users with security guidance.
Updates the SIEM with an incident record for correlation and compliance.
Result: Compromised accounts are secured, and users are alerted before threat actors can exploit access.
Threat Intel + Phishing Detection
Scenario: A user reports a suspicious email via the company’s phishing reporting button.
How Torq Handles It:
The reported email is sent to Torq via Microsoft 365 Security or Proofpoint TAP integration.
Torq extracts sender domains, IPs, and embedded URLs.
Those indicators are checked against:
External threat intel feeds like AlienVault OTX and Abuse.ch.
Internal blocklists and historical case data in Torq.
If confirmed malicious, Torq:
Quarantines the email for all recipients at the email gateway.
Blocks the domain in the web proxy.
Notifies the reporting user with a “verified malicious” confirmation.
Result: A single user report becomes a fully automated, organization-wide protection action.
Scalable Enrichment Without Developer Overhead
Scenario: The SOC wants to enrich all IOC feeds with cross-platform intelligence but lacks developer bandwidth.
How Torq Handles It:
An analyst drags and drops connectors for Recorded Future, VirusTotal, AbuseIPDB, and MISP into the workflow canvas.
Using Torq’s no-code visual editor, the analyst chains enrichment steps, scoring logic, and conditional response rules.
New threat intel feeds can be added in minutes, and workflows update automatically without engineering intervention.
Result: The SOC scales enrichment capabilities rapidly, integrating multiple TI sources and incident response actions without waiting on dev cycles.
Threat Intelligence Is Only as Good as the Action It Enables
Threat intelligence is the spark that ignites detection, but it’s the action you take with that intelligence that determines whether it prevents an attack or becomes just another line in a report. Without automation, even the most curated and timely feeds leave SOC teams drowning in manual triage, correlation, and remediation steps.
The challenge is operationalizing threat intelligence at machine speed, ingesting, validating, enriching, and acting on it in seconds, not hours. That requires an automation platform that connects intelligence sources directly to your detection, investigation, and response layers.
What to Look for in an Automated Threat Intelligence Stack
To fully realize the value of your threat intel, your automation stack should deliver:
Interoperability: Native integrations with SIEM, SOAR, EDR, firewall, email security, and CTI feeds so threat data flows seamlessly across tools.
Real-time enrichment: The ability to instantly enhance IOCs with reputation scores, geo-location, WHOIS data, historical activity, and related incidents, and feed that context back into detection and response systems.
Scalability: Capacity to process thousands (or millions) of IOCs per day without slowing down, whether from burst attack campaigns or ongoing intelligence streams.
No-code flexibility: The option for analysts to adapt, expand, or fine-tune workflows without relying on developer resources, so you can pivot quickly to new threats.
Why Torq Is Built for Modern Threat Detection
Torq’s Hyperautomation Platform turns raw threat intel into orchestrated action across your SOC. It’s designed to:
Automate at scale with autonomous runbooks that can process and act on high IOC volumes without analyst intervention.
Integrate instantly using agentless, native connectors to 1,000+ tools — from threat intel platforms like Recorded Future, VirusTotal, and MISP to your SIEM, EDR, and firewall stack.
Enable SOC agility through a visual no-code/low-code editor and AI workflow building, so analysts can build or modify enrichment and incident response workflows in minutes.
Drive immediate outcomes — blocking malicious IPs, quarantining emails, disabling compromised accounts, or alerting security analysts— all triggered by enriched intel in real time.
With Torq, threat intelligence isn’t just data; it’s a live signal that moves seamlessly from detection to decision to remediation, without manual processing delays.
Implementation Guide: Setting Up Automated Threat Intelligence Workflows
Knowing which threat intelligence tools to use is one thing. Getting them working together in a way that actually reduces analyst workload and accelerates response is where most teams hit friction. This guide walks through how to approach each major integration type, what to configure, and what to watch for as you build out automated enrichment pipelines.
Connecting Threat Intelligence Feeds
The first step in any automated threat intelligence workflow is establishing reliable, consistent data ingestion from your chosen feeds. Most commercial and open-source threat feeds support one of two delivery mechanisms: REST API polling, where your automation platform queries the feed on a schedule, or webhook push, where the feed sends data to your platform in real time when new indicators are published.
For polling-based feeds like VirusTotal and AbuseIPDB, the key configuration decisions are polling frequency and rate limit management. Both platforms enforce API rate limits that vary by subscription tier. The practical approach is to set polling intervals that match your threat response SLA — if your goal is to act on a new IOC within 15 minutes of publication, a 10-minute polling interval is appropriate — and build rate limit handling into your workflow so that temporary limit hits pause and retry rather than fail silently.
For webhook-based delivery — common with commercial platforms like Recorded Future — the integration involves registering a webhook endpoint in your automation platform and configuring the feed provider to push alerts to that endpoint. Torq’s webhook trigger capabilities handle this natively, receiving the inbound payload, parsing the structured data, and passing it into the enrichment workflow automatically.
Authentication across most major feeds follows one of two patterns: API key authentication passed as a header, or OAuth 2.0 for platforms requiring scoped access tokens. The operational best practice is to store credentials in a secrets manager rather than embedding them directly in workflow configurations, and to rotate keys on a defined schedule. Most enterprise-grade automation platforms, including Torq, support secrets management natively so credentials are never exposed in workflow logic.
Building Automated Enrichment Pipelines
An enrichment pipeline is a structured sequence of data lookups that transforms a raw indicator into a contextualized, scored, and actionable security event. A well-designed pipeline runs these lookups in parallel rather than sequentially — querying VirusTotal, AbuseIPDB, and WHOIS simultaneously rather than one after another — which reduces total enrichment time from minutes to seconds.
The practical components of a production enrichment pipeline are:
Indicator extraction: Parsing the incoming alert or feed event to extract the raw indicator — IP address, domain, file hash, or URL — in a normalized format that downstream lookups can consume consistently.
Parallel enrichment queries: Simultaneously querying each intelligence source and collecting responses. The key design principle here is that each query should be independent — a timeout or error from one source should not block the others from returning results.
Scoring and confidence assignment: Aggregating the results from multiple sources into a unified risk score. The most common approach is weighted scoring, where a high-confidence commercial feed like Recorded Future carries more weight than a community feed, and detections across multiple independent sources increase the score. Define score thresholds before deployment — for example, score 0-30 closes automatically as low risk, 31-70 queues for analyst review, 71-100 triggers immediate automated response.
Conditional response logic: Branching the workflow based on the score and context. High-scoring indicators with confirmed internal matches trigger containment. Medium-scoring indicators with no internal match get logged and monitored. Low-scoring indicators are closed with documentation.
Integrating with STIX/TAXII Feeds
STIX (Structured Threat Information eXpression) and TAXII (Trusted Automated eXchange of Intelligence Information) are the dominant open standards for structured threat intelligence sharing. STIX defines what threat intelligence looks like — the data model for indicators, campaigns, threat actors, TTPs, and relationships between them. TAXII defines how that intelligence moves between systems — the transport protocol and API structure for publishing and consuming STIX content.
In practice, integrating a TAXII feed means pointing your automation platform at a TAXII server’s collection endpoint, authenticating with the credentials provided by the feed operator, and specifying which collection you want to consume and at what polling interval. The TAXII server returns STIX bundles — JSON objects containing one or more STIX objects with defined types such as indicator, threat-actor, malware, or attack-pattern.
The operational challenge with STIX/TAXII feeds is data volume and relevance filtering. Enterprise TAXII feeds can publish thousands of STIX objects per day, the majority of which may not be relevant to your environment. The right approach is to filter at ingestion — using indicator type, confidence score, and TLP (Traffic Light Protocol) marking to discard low-value objects before they enter your enrichment pipeline — rather than trying to process everything and filter downstream.
Torq connects to TAXII 2.1 servers natively, handles STIX bundle parsing, and allows analysts to configure relevance filters visually without writing parsing code. This means teams without dedicated threat intelligence engineering resources can still consume structured intelligence feeds at scale.
Managing Feed Quality and Reducing False Positives
Feed quality is the most underappreciated variable in threat intelligence automation. A high-volume, low-confidence feed that generates thousands of IOCs per day sounds valuable but often produces more noise than signal — overwhelming enrichment pipelines, inflating false positive rates, and eroding analyst trust in automated verdicts.
The practical approach to feed quality management involves three controls.
First, apply confidence thresholds at ingestion — most commercial feeds include a confidence score on each indicator, and setting a minimum threshold (typically 70 or above on a 100-point scale) filters out speculative or unverified indicators before they enter the pipeline.
Second, implement expiry logic. Threat indicators have a natural shelf life — a malicious IP that was active six months ago may now host legitimate traffic. Most well-maintained feeds include expiry timestamps on indicators. Your workflow should respect these, automatically removing expired indicators from active blocklists and enrichment lookups rather than accumulating stale data indefinitely.
Third, track false positive rates per source. If a specific feed consistently generates indicators that your analysts mark as irrelevant or benign, that feed’s weight in your scoring model should decrease accordingly. Over time, this feedback loop improves the accuracy of automated verdicts without requiring manual tuning of individual indicators.
Common Integration Challenges and How to Solve Them
Rate limiting: Most commercial threat intelligence APIs enforce rate limits that can interrupt automated workflows during high-alert-volume periods. Solve this by implementing exponential backoff retry logic — when a rate limit error is returned, the workflow waits progressively longer before retrying — and by prioritizing high-severity alerts for immediate enrichment while batching lower-priority indicators for off-peak processing.
Data format inconsistency: Different feeds return data in different formats and schemas, which creates normalization overhead in enrichment pipelines. The most durable solution is a normalization step at the ingestion layer — transforming each feed’s output into a consistent internal schema before it enters the enrichment pipeline — so downstream workflow logic can rely on a predictable data structure regardless of the source.
Feed overlap and indicator duplication: The same malicious IP or domain often appears across multiple feeds simultaneously, which can inflate risk scores if deduplication is not handled correctly. Implement deduplication logic that checks whether an indicator already exists in an active investigation or blocklist before creating a new enrichment task, and merge scores from multiple sources into a single consolidated verdict rather than treating each feed hit as an independent event.
Latency in high-volume environments: Enrichment pipelines that run fully sequentially slow down under high alert volume. Parallel query execution — running multiple intelligence lookups simultaneously rather than one after another — is the most effective way to reduce per-alert enrichment time as volume scales.
Categories of Threat Intelligence Tools Cybersecurity Teams Rely On
Category
Workflow Stage
Purpose
Where Torq Fits
Example Tools
Threat Data Aggregators & Feeds
Collect → Normalize
Centralize raw intel from OSINT, dark web, vendor feeds
Ingests IOCs, auto-dedupes, normalizes to STIX/TAXII, applies TTL, routes to SIEM/EDR with guardrails
AlienVault OTX, Abuse.ch, Recorded Future
Threat Analysis & Correlation
Enrich → Analyze → Hunt
Link IOCs to malware families, campaigns, actors
Automates enrichment and correlation, captures analyst pivots as runbooks, pushes TTPs back to detection
ThreatConnect, Anomali, VirusTotal
Alert Prioritization & Risk Scoring
Triage → Prioritize
Rank alerts by risk and asset criticality
Auto-escalates high-risk alerts, auto-suppresses noise, learns from analyst feedback
Splunk ES, Cisco SecureX, Exabeam
Threat Intelligence Sharing & Collaboration
Share → Collaborate → Govern
Distribute intel across teams & communities
Auto-ingests shared intel, validates, enriches, deploys, feeds outcomes back to community
MISP, OpenCTI, ISAC Portals
Advanced Threat Intelligence Concepts
The Four Types of Threat Intelligence
Here is what each one actually means in practice for the teams consuming it, and how each type flows into your automation stack differently.
Strategic intelligence addresses the question executives and board members ask: what is the threat landscape doing to our business risk? Strategic intelligence arrives as finished reports, briefings, and trend analyses — not raw indicators. It informs budget decisions, vendor selection, and security program priorities. Strategic intelligence does not feed directly into automated workflows; it informs the humans who design those workflows and set organizational risk thresholds.
Operational intelligence addresses the question SOC leads and incident responders ask: what is this specific adversary doing right now, and what does it mean for us? Operational intelligence covers active campaigns, adversary infrastructure, and the specific TTPs a threat actor is using in the current attack cycle. It feeds into detection rule creation, threat hunting hypothesis development, and playbook updates. Operationally, this means your threat intelligence platform receives a new campaign report, extracts the associated IOCs and TTPs, maps them to MITRE ATT&CK, and pushes new detection rules to your SIEM — automatically.
Tactical intelligence addresses the question SOC analysts ask during active investigations: is this specific indicator malicious, and how bad is it? Tactical intelligence consists of IOCs — IP addresses, domains, file hashes, URLs — with associated confidence scores, expiry dates, and context. This is the intelligence type that feeds directly into real-time automated enrichment pipelines. Tactical indicators have short shelf lives and must be managed with expiry logic to prevent stale data from generating false positives.
Technical intelligence addresses the question detection engineers and threat hunters ask: how does this threat actually work, and how do I build a detection for it? Technical intelligence includes malware samples, YARA rules, Sigma rules, behavioral indicators, and vulnerability details. It feeds into detection engineering workflows — automatically pushing new YARA rules to sandboxes, new Sigma rules to SIEMs, and new vulnerability identifiers to vulnerability management platforms when published by trusted sources.
Threat Intelligence Data Standards
STIX 2.1 (Structured Threat Information eXpression) is the current standard for representing threat intelligence as structured data. A STIX bundle contains typed objects — indicators, threat actors, malware, attack patterns, campaigns, and relationships between them — in JSON format. The key advantage of STIX 2.1 over earlier formats is the relationship object, which allows explicit connections between intelligence objects to be represented and queried. An indicator can be linked to the malware family it detects, which is linked to the threat actor that uses it, which is linked to the campaign it supports — creating a queryable intelligence graph rather than a flat list of IOCs.
TAXII 2.1 (Trusted Automated eXchange of Intelligence Information) is the transport protocol that moves STIX content between systems. A TAXII server exposes collections — logical groupings of STIX content — that clients poll or subscribe to. TAXII 2.1 uses standard HTTPS with JSON payloads, which makes it significantly easier to integrate than earlier versions that required specialized client libraries.
MISP (Malware Information Sharing Platform) is an open-source threat intelligence platform widely used in ISACs, government CERTs, and community sharing groups. MISP uses its own attribute-based data model but supports STIX export, making it interoperable with TAXII consumers. MISP’s galaxy feature provides a structured taxonomy for threat actors, malware families, and attack techniques that maps closely to MITRE ATT&CK.
OpenIOC is an older XML-based standard for expressing indicators of compromise, primarily used in incident response and forensic contexts. While largely superseded by STIX for new integrations, many legacy tools and historical intelligence repositories still use OpenIOC format — meaning production enrichment pipelines often need to support both STIX and OpenIOC parsing.
IOC Confidence Scoring
Confidence scoring is the mechanism that transforms raw intelligence into actionable, prioritized verdicts. A well-designed confidence scoring model accounts for three variables: source reliability, indicator freshness, and corroboration.
Source reliability reflects how consistently accurate a specific feed or platform has been historically. A commercial platform with rigorous analyst validation carries higher baseline reliability than an automated community feed. Reliability scores are typically assigned per source and updated over time based on observed false positive rates.
Indicator freshness reflects how recently the indicator was observed in malicious activity. Most intelligence platforms timestamp indicators with a first-seen and last-seen date. An indicator last seen actively attacking systems 48 hours ago is significantly more relevant than one last seen six months ago, and your scoring model should discount older indicators accordingly.
Corroboration reflects how many independent sources have confirmed the indicator as malicious. An IP address flagged by a single feed carries less confidence than one flagged independently by three different platforms. Corroboration across unrelated sources is the strongest signal of genuine maliciousness, and automated scoring should weight multi-source confirmation heavily.
In practice, automated scoring typically produces a normalized score on a 0-100 scale. Scores above 70 trigger immediate automated response. Scores between 40 and 70 queue for analyst review with full context. Scores below 40 log for monitoring but take no active action. The exact thresholds depend on your organization’s risk tolerance and the volume of indicators your pipeline processes daily.
Threat Hunting with Automated Intelligence
Threat hunting is the proactive practice of searching for adversary activity that has not yet triggered automated alerts. Intelligence-driven threat hunting uses threat intelligence — specifically operational and technical intelligence — to generate hypotheses about what an adversary might be doing in your environment, then systematically tests those hypotheses against your telemetry.
The automation opportunity in threat hunting is hypothesis execution, not hypothesis generation. Human hunters define the hunt — based on a new threat report, a published TTP, or an emerging campaign — and automation executes the search across the full environment at machine speed. Rather than a hunter manually writing and running queries across multiple tools, an automated hunt workflow executes parallel searches across EDR, SIEM, cloud logs, and identity systems simultaneously, surfaces matches, and delivers structured findings to the hunter for analysis.
Torq supports automated threat hunting by connecting hunt workflows to intelligence sources — when a new campaign report publishes associated TTPs, Torq can automatically execute hunt queries across your stack for those specific behavioral patterns, delivering results to analysts without requiring manual query construction or tool-by-tool searching.
Intelligence Fusion
Intelligence fusion is the practice of combining multiple intelligence sources — commercial feeds, open-source feeds, internal telemetry, and community sharing — into a unified, deduplicated, and corroborated picture. The operational goal is to eliminate the blind spots that exist when each source is consumed in isolation and to surface correlations that only become visible when data from multiple sources is analyzed together.
In automated intelligence fusion pipelines, each intelligence source feeds into a central normalization layer that standardizes data formats, assigns source reliability weights, deduplicates overlapping indicators, and produces a unified indicator store that downstream enrichment workflows query. This unified store is more accurate and more relevant than any single source — a critical advantage when automated workflows are making containment decisions without human review.
Performance Optimization for High-Volume Environments
Feed prioritization: Not all intelligence sources deliver equal value for every organization. Prioritize feeds that have demonstrated high relevance to your specific industry, geography, and technology stack. A financial services firm benefits more from feeds specializing in banking trojans and fraud infrastructure than from broad-spectrum feeds optimized for manufacturing sector threats. Regularly review false positive rates and action rates per feed — if a feed consistently generates IOCs that result in no action, reduce its weight in your scoring model or discontinue it.
Data deduplication: Production enrichment pipelines accumulate duplicate indicators quickly, especially when consuming multiple feeds that overlap in coverage. Deduplication at ingestion — checking each new indicator against a hash of currently active indicators before adding it to the pipeline — prevents the same IP or domain from triggering multiple parallel enrichment tasks and inflating workload.
Caching enrichment results: Many enrichment lookups return the same result for the same indicator across multiple queries within a short timeframe. Implementing a short-term cache — storing enrichment results for a defined TTL, typically one to four hours depending on the feed’s update frequency — eliminates redundant API calls for recently seen indicators, reducing both API costs and enrichment latency during high-volume alert periods.
Tiered processing: Not every alert warrants the same depth of enrichment. A tiered approach processes high-severity alerts with the full enrichment pipeline immediately while batching lower-severity alerts for less time-sensitive processing. This prevents high-alert-volume periods from overwhelming enrichment capacity and ensures the most critical threats receive the fastest response.
Operationalize Threat Intelligence Tools with Torq
Great threat intelligence tools surface what’s out there; Torq turns that signal into outcomes. By ingesting feeds and TIPs, normalizing to common schemas, enriching with WHOIS/GeoIP/reputation, and correlating against your SIEM/EDR/IAM telemetry, Torq’s no-code Hyperautomation moves from detect to resolve in seconds — automatically.
Pre-approved playbooks block domains and IPs, isolate endpoints, revoke access, and notify stakeholders in chat, all with full audit trails and role-based control. The result: lower MTTR, less downtime, fewer manual escalations, a stronger security posture, and a calmer on-call.
If you’re investing in threat intelligence tools but still triaging by hand, you’re leaving value on the table. Pair your intel with automation that’s interoperable, explainable, and scalable so every high-confidence indicator translates into immediate, governed action.
Ready to turn intel into impact? See how Torq can help make your SOC more efficient.
Examples of threat intelligence include malicious IP addresses, suspicious domain names, file hashes associated with malware, phishing email indicators, and known threat actor infrastructure. More advanced threat intelligence also includes TTPs (tactics, techniques, and procedures) tied to specific threat actors.
What are the four types of threat intelligence?
Strategic: High-level trends and risks for executive decision-making.
Tactical: Information on adversary TTPs for defensive planning.
Operational: Intel on active campaigns and imminent threats.
Technical: Raw indicators like IOCs for detection and blocking.
What are six major sources of cyber threat intelligence?
Commercial CTI platforms (e.g., Recorded Future, Mandiant Advantage)
Security product telemetry (SIEM, EDR, XDR)
Dark web monitoring
Industry sharing groups (ISACs/ISAOs)
Government or law enforcement alerts (e.g., CISA, FBI)
What are the best free cyber threat intelligence feeds?
Popular free feeds include AlienVault OTX, Abuse.ch, MalwareBazaar, URLhaus, and various ISAC community feeds. While valuable, they should be supplemented with commercial feeds and automated enrichment for best results.
What does threat intel do?
Threat intelligence helps security teams understand, anticipate, and respond to cyber threats by providing context, patterns, and IOCs that inform detection and incident response workflows.
What are feeds in cybersecurity?
A threat feed is a continuously updated stream of IOCs and threat data that can be ingested into cybersecurity tools like SIEMs and SOAR platforms to enhance detection.
What are examples of threat feeds?
Examples of threat feeds include IP blocklists, malicious domain lists, malware hash databases, and phishing URL repositories.
What is threat feed vs threat intelligence?
Threat feed: A raw data stream containing IOCs.
Threat intelligence: Enriched, analyzed, and contextualized data derived from one or more feeds, ready to be used in decision-making and automated workflows.
Noam Cohen is a serial entrepreneur building seriously cool data and AI companies since 2018. Noam’s insights are informed by a unique combination of data, product, and AI expertise — with a background that includes winning the Israel Defense Prize for his work in leveraging data to predict terror attacks. As the Head of Artificial Intelligence at Torq, Noam is helping build truly next-gen AI capabilities into Torq’s autonomous SOC platform.
Still obsessing over compliance certifications and data volumes when choosing your AI SOC analyst? You might as well be that guy at the dealership kicking tires and demanding V8 specs while ignoring the self-driving capabilities.
Today’s CISO battlefield isn’t won with yesterday’s metrics. While AI security vendors sell you on training corpus size and customization options, you should be demanding zero-day detection without signatures and unified threat visibility.
Let’s be brutally honest: the blistering pace of AI innovation means your current AI SOC evaluation checklist is obsolete. GenAI marked an inflection point; now, agentic AI is completely disrupting SecOps. This means the real competitive edge lies in capabilities your procurement team isn’t even asking about.
So, what should CISOs look for in an AI SOC analyst? Below, we break down 8 key capabilities that you might not have considered but are crucial to ensure AI trust and effectiveness in your SOC.
What to Look for in an AI SOC Analyst Evaluation
1. AI That Simplifies and Communicates Context
Look for: Next-gen AI for the SOC that shows sophistication beyond query-response models, demonstrating a nuanced understanding and delightful communication of organizational context, ongoing security incidents, and specific scenarios.
Rather than summarizing in a generic “TL;DR” format, the AI should communicate about logs, case artifacts, and indicators of compromise (IOCs) through a cybersecurity-oriented UI that highlights key information for the specific security context.
Ask:
Can the AI maintain contextual continuity across analyst shifts and SOC handoffs?
How does the chat UI maintain context for the user when referencing information-heavy items like logs and cases?
Does the AI have different user views for summarizing actions, IOCs, and alerts?
Where can I embed our knowledge and policies to guide the AI’s interactions?
General example:
General example showing how a smart reference summarization popup from Arc (The Browser Company) helps users quickly understand selected text or an entire webpage without leaving their current browser.
2. AI for the Entire Team
Look for: Practical AI capabilities mapped explicitly to real-world SOC workflows and use cases.
The AI SOC analyst should do the actual, gritty tasks your SOC team performs daily — from initial triage to investigating alerts, hunting for threats, and remediating problems. This isn’t about general intelligence; it’s about directly supporting actual analyst workflows from end to end. If you use a multi-agent system (MAS), the AI SOC analyst should act as an OmniAgent to coordinate and collaborate with multiple specialized AI agents to accomplish these complex security goals.
Ask:
What analyst-level jobs does the AI accelerate (e.g. query writing, unstructured enrichment, and response recommendations)?
How does the AI SOC agent accelerate threat hunting and detection engineering through intelligent hypothesis generation?
Is the system capable of auto-healing errors in security workflows the way a good security engineer can?
General example:
General example showing how Gemini’s Gem store features different chatbots for Marketing, Sales, and Developers.
3. AI That Explains What It’s Doing
Look for: AI that grounds its findings and recommendations in clear, structured explanations showing its sources.
CISOs increasingly prioritize “explainability” in AI decisions as a pragmatic imperative for achieving cognitive alignment between the AI SOC analyst and the human security team. To foster trust, adoption, and effective action, your security team must have a line of sight into the AI’s reasoning, not just its conclusions.
Ask:
Does the AI SOC analyst clearly explain why particular security events are flagged or escalated?
How easily can human analysts validate or challenge the AI’s recommendations? For instance, can they request source links, exact quotes, or highlighting?
Do we have visibility into the AI agent’s self-critique step?
General examples showing how two AI models show the data it relies on. Perplexity shows a snippet of the source while NotebookLM highlights the exact sentence it used from the source.
4. AI That’s Easy to Interact With — Without Training
Look for: A SOC-specific user interface that is genuinely intuitive, innovative, and frictionless and that directly enhances analyst productivity, retention, and job satisfaction.
Even the most powerful AI can be hampered by a clunky or difficult interface, undermining your team’s effectiveness and morale and discouraging AI adoption. A truly innovative interface should feel natural to use and streamline workflows, not add complexity or friction to processes. An intuitive design enables analysts of any level to quickly access insights and take action without specialized skills or knowledge.
Ask:
How much do our human analysts need to be familiar with AI hacks and general prompt engineering, such as knowing when to use deep search options, ask for a specific data format, or open a new conversation thread?
Does the AI SOC analyst support conversational SIEM queries and natural-language threat exploration?
How does the AI communicate its planning and thinking process?
In autopiloting, can I interrupt the investigation before the AI is done?
General example:
General example showing how Perplexity creates a simpler user experience by auto-choosing the model according to its research, rather than making the user choose a model by task/prompt.
5. AI That Helps You Get Ahead
Look for: An AI SOC analyst that doesn’t only react to known threats but proactively guides SOC teams towards improving security posture and operational effectiveness.
Think of your top analysts — the ones who are always one step ahead, anticipating your team’s needs and suggesting improvements without being asked. Agentic AI that performs at this advanced level can act as a virtual extension of your team, identifying weaknesses and suggesting optimizations to elevate your security operations.
Ask:
Can the AI SOC analyst proactively detect and suggest SOC operational improvements, such as recommending repetitive manual processes that are ripe for automation?
Can it automatically correlate cases with incident history and recommend improvements?
Has your AI ever caught a missing step in its instructions and fixed it (or asked about it) before executing?
Can the AI automatically tag and store important information from your interactions that can help in future cases?
Will the AI suggest changes to the detection rules, workflows, or playbooks? How often does your AI flag inefficiencies in workflows?
General example:
General example of ChatGPT maintaining context after you’ve told it that you are an AI product manager in San Francisco. When asking it to brainstorm messaging for a social post celebrating an achievement, ChatGPT already knows where to start.
6. AI That Understands What You Really Want (and Can Figure Out How to Do It)
Look for: Deterministic, agentic AI that understands how to break a user intent into multiple tasks, which may require different execution plans.
Good AI gets a task and starts working. Great AI first looks for communication gaps, understands the goal, and asks for more instructions when needed. Ideally, the user shouldn’t have to think like the AI to ensure the AI grasps their intent — the AI should understand how the user thinks and ask clarifying questions when needed.
A structured execution scheme reduces ambiguity and improves the accuracy of the AI’s planning and orchestration, eliminating the likelihood of the AI agent skipping steps, going out of order, selecting incorrect tools, or misinterpreting instructions.
Ask:
When I give the AI a vague or complex instruction, does it ask clarifying questions — or just charge ahead?
How does it use screens, user information, and past sessions to better understand the user’s specific intent?
Can your AI break down a high-level goal (‘Investigate this alert’) into a sequence of logically ordered tasks — and tell you why?
Can your AI explain its execution plan in plain language before it starts and adjust if you push back?
General example:
General example showing how ChatGPT asks clarification questions before building a report in Deep Research.
7. An AI Assistant That You Don’t Need to Babysit
Look for: Agentic AI capable of autonomously chaining together multiple actions without constant human prompts.
Your human analysts don’t want to click through 10 steps every time they need the AI to take action. While human oversight of critical decisions is important, to efficiently investigate an alert end-to-end and even initiate containment, an AI SOC analyst must be capable of independently stringing together a sequence of relevant subtasks — like log collection, enrichment, reverse engineering, and containment suggestions — in pursuit of a high-level goal.
Ask:
Can the AI SOC analyst complete a multi-step investigation with one high-level instruction?
Can the AI write and execute deterministic workflows when needed?
Does it pause and check with human analysts before executing sensitive tasks (e.g., blocking users or IPs)?
When given a high-level goal or non-playbook scenario, does the AI independently decide which steps to take and in what order?
How does the AI identify when not to act — and escalate to a human when it hits a confidence or authority threshold?
General example:
General example of how Intercom’s Fin interface defines the moments where a human needs to be looped into the convo.
8. AI That Gets More Helpful Through Human Feedback
Look for: An AI SOC analyst that continuously learns and improves by observing and incorporating feedback from human analyst behavior.
The best AI SOC analysts learn from human analyst behavior to become more effective and accurate over time. Think of it as shaping the ideal analyst that shadows your team, watches how they triage alerts, write queries, and handle false positives — and gets smarter with every interaction.
Human analysts should be able to fine-tune and correct AI as threats evolve rather than treating it as a black box. In practice, features like thumbs-up/down ratings, interactive retraining, or the ability to override AI decisions make the human–AI loop tighter and more effective.
Ask:
How does the AI SOC analyst adapt based on human analysts’ corrections or preferences over time?
Can I adjust the AI’s prioritization or response style via feedback?
How can the user flag a successful conversation with the AI to make future sessions easier and more effective?
Can you review and audit what the AI has learned from your team?
General example:
General example showing how Cursor’s Coding Rules feature helps developers continuously improve and adapt their preferences using natural language.
Next-Gen AI for the SOC is Here — Are You Ready?
Don’t be the security leader who marvels at a shiny paint job while ignoring the revolutionary engine. When evaluating AI SOC analysts, focus on explainable intelligence, seamless integration into your team’s workflow, and deterministic AI that can independently plan and orchestrate all of the actions required to complete a high-level goal from end to end.
Finding an AI SOC analyst that truly understands context, empowers your analysts, and acts with proactive autonomy will ensure you’re not just keeping up with the latest tech but investing in a force multiplier for your security team.
Get the AI or Die Manifesto to learn strategic considerations, get insights from a CISO, and learn red flags and more questions to ask for an AI SOC evaluation.
Phishing has evolved from a nuisance into a full-blown crisis for SOC teams. Once easy to spot, today’s phishing emails are polished, personalized, and powered by generative AI — enabling attackers to launch thousands of realistic campaigns in minutes.
SOCs are drowning in suspicious email reports, with analysts forced to inspect headers, attachments, and URLs at scale manually. Even worse, over a majority of end-user reports turn out to be false positives, meaning hours of wasted effort chasing noise instead of responding to real threats.
Why Phishing Analysis Overwhelms SOC Teams
Phishing isn’t just the most common cyberattack; it’s also one of the most draining for security teams. Attacks have increased 49% since 2021, with each successful breach costing organizations nearly $5M on average. GenAI has fueled a 4,151% increase in phishing campaigns since 2022, so the volume and realism of phishing attempts are outpacing traditional defenses.
Phishing analysis is the process of examining suspicious emails to identify and mitigate phishing attacks. This involves scrutinizing various aspects of the email, including sender details, content, and attachments, to detect signs of malicious intent. It’s a critical component of cybersecurity, helping organizations protect themselves from data breaches and other cyber threats.
For SOC analysts, every reported phishing email can become a time sink. Investigations require painstaking review of headers, attachments, URLs, and sender reputation checks — often across multiple tools. A Microsoft study found 90% of user-reported phishing emails turn out to be false positives, yet each still consumes valuable analyst time. At scale, that means thousands of hours spent chasing noise while real threats risk slipping through the cracks.
This perfect storm of higher alert volume, more sophisticated lures, and limited staff creates an unsustainable workload. Instead of focusing on strategic tasks like threat hunting or incident response, analysts get buried in repetitive phishing checks. The result: Burnout, alert fatigue, and delayed response times that adversaries exploit to their advantage.
With the help of automation taking over the repetitive triage and enrichment tasks that bog analysts down, platforms like Torq HyperSOC™ slash analysis times from hours to minutes, eliminate the majority of false positives, and free security teams to focus on threats that actually matter.
How to Automate Outlook Mailbox Monitoring with Torq
Torq HyperSOC™ includes ready-to-run templates that transform your phishing inbox into an always-on, case-driven automation pipeline. Here’s how it works end-to-end, plus the setup details, best practices, and guardrails that make it safe at scale.
1. Turn Your Mailbox into an Always-On Detection Pipeline
Instead of relying on analysts to check a shared phishing inbox, Torq connects directly to Microsoft Outlook using Microsoft Graph API. A dedicated mailbox (for example, [email protected]) becomes an automated trigger point, and every new report instantly kicks off an enrichment and triage workflow. This integration is secure by design, using least-privilege permissions and admin-controlled access policies to keep everything locked down.
2. Automate the Analysis
Once a message lands, Torq automatically extracts and analyzes the essential data: headers, links, attachments, sender reputation, and user context. Behind the scenes, AI and security Hyperautomation handle all the enrichment tasks that typically burn analyst time — checking SPF/DKIM, scanning URLs and attachments, detonating files in sandboxes, and cross-referencing with threat intel. This leaves analysts with a fully scored, context-rich case that tells you whether it’s safe, suspicious, or malicious, all before a human ever touches it.
3. Respond at Machine Speed
When Torq confirms a threat, response happens automatically but safely. The platform can:
Quarantine malicious emails organization-wide
Block domains or senders
Isolate infected endpoints or reset credentials through integrated EDR and IAM tools
Notify users with templated guidance (e.g., “Did you click…?”) for added validation
Log every action, approval, and artifact in a complete, auditable case file
Everything runs according to your organization’s policies; automation never overrides human approval for sensitive actions.
4. Get Case Management That Writes Itself
Each investigation is automatically converted into a structured case, complete with enriched data, screenshots, indicators, and an easy-to-read AI-generated summary. Analysts can quickly review, bulk-close false positives, or pivot into related cases for campaign hunting — all from a single workspace.
What once took hours now happens in seconds, freeing your team to focus on strategy and proactive threat hunting instead of inbox cleanup.
5. Enforce AI Guardrails
Automation at scale only works if it’s safe, and Torq was built with that in mind. Every workflow runs with built-in AI governance, compliance, and resiliency features designed for enterprise SOCs and MSSPs.
Least-privilege access: Microsoft Graph permissions are scoped to a single mailbox or folder, minimizing exposure.
Role-based access controls (RBAC) and approvals: Sensitive actions like global purges or account disables always require the right role or human confirmation.
Self-healing subscriptions: Torq automatically monitors Microsoft Graph subscriptions, renews them before expiration, and alerts if something drifts.
Resilient error handling: Smart retries and throttling logic keep automations stable under API load or transient faults.
MSSP-ready tenant isolation: Shared automations can be cloned per customer, ensuring strict data separation with zero cross-tenant risk.
6. Experience What “Good” Looks Like
A well-built phishing response automation doesn’t just run — it delivers measurable impact. Here are the key KPIs that show it’s working:
Faster MTTD / MTTR: Phishing cases identified and contained in minutes, not hours
Broader automation coverage: A growing percentage of Tier-1 triage handled end-to-end with zero human touch
Reduced false positives: Fewer manual reviews and cleaner queues for analysts
Better purge performance: Malicious messages removed across mailboxes more quickly and completely.
Higher user engagement: High confirmation rates and faster user responses to “Did you click?” checks
Improved analyst efficiency: Hours reclaimed per case — often hundreds of hours per quarter — that can be reinvested into proactive security work
When these numbers start trending up and manual reviews drop off, that’s when you know your automation is transforming the SOC.
Faster, Smarter, and Scalable Phishing Analysis
Torq cuts phishing triage from hours to minutes. Automated enrichment includes:
DMARC/SPF analysis to validate sender reputation
URL screenshotting to detect impersonation
Sandbox detonations and IOC checks for attachments
AI-generated summaries of findings, ready for analyst review
The outcome: faster investigations, fewer false positives, and higher analyst efficiency.
Torq Makes Traditional Phishing Analysis Tools Better
No/low-code flexibility: Build workflows in minutes.
Agentic AI: Summarizes, enriches, and prioritizes phishing cases.
300+ integrations: Connects to your SIEM, EDR, IAM, ITSM, and email stack.
Scalability: Automate phishing triage across thousands of alerts with no extra headcount.
Make Phishing Analysis Autonomous
Phishing isn’t slowing down — but your team doesn’t have to slow down with it.
With Torq HyperSOC™, phishing analysis becomes fast, reliable, and fully automated. Every reported email is enriched, scored, and resolved in minutes, with full visibility and control. By turning repetitive triage into efficient and autonomous workflows, Torq helps SOCs reclaim time, eliminate false positives, and focus on stopping real threats before they spread.
Check out our SOC Efficiency Guide for tips on squeezing the most out of your SOC processes, people, and tech stack.
Phishing analysis includes investigating an email to determine whether it’s malicious or benign. Analysts inspect elements like the email header, sender domain, URLs, and attachments to uncover signs of spoofing or social engineering. Using automation tools such as Torq HyperSOC™, SOC teams can quickly analyze large volumes of suspicious emails across the mailbox to identify real threats while reducing manual workload.
How can you identify phishing emails?
You can identify a phishing email by examining inconsistencies in the sender address, checking the email header for mismatched domains, and inspecting embedded URLs for redirects or spoofed links. Poor grammar, unexpected attachments, and urgent requests for sensitive information are common warning signs. Modern email security tools and phishing analysis tools help automate these checks by performing authentication validation (SPF, DKIM, DMARC) and sandbox testing.
What are the signs of a phishing email?
A suspicious email often contains subtle red flags, such as a spoofed display name, forged sender authentication headers, or URLs that impersonate legitimate brands. Malicious emails may include weaponized attachments, such as PDFs or Office documents containing macros. By analyzing the email header and sender authentication results, SOC teams can determine whether the threat is credible. Automated analysis tools like Torq can perform these verifications instantly.
Can phishing analysis be automated?
Absolutely. With a modern security automation platform like Torq, the entire phishing analysis process — from mailbox monitoring to threat enrichment and response — can be automated safely and effectively. Automated workflows extract data from the email header, verify sender authentication, assess URLs and attachments, and classify each message as benign, suspicious, or malicious. Guardrails such as RBAC, approval flows, and secure integrations ensure that automation never acts on false positives or spoofed alerts.
Why is phishing analysis important for SOC teams?
Phishing analysis is foundational to modern email security because it enables organizations to detect malicious messages that slip past traditional filters. Attackers often exploit trust in familiar senders or use spoofed domains to steal sensitive information like credentials or financial data. Automated phishing analysis tools correlate data across multiple sources — including the email header, authentication records, and threat intel feeds — to identify and neutralize these threats before they reach users.
How does Torq differ from traditional phishing tools?
Torq combines no-/low-code automation with AI-driven phishing analysis to streamline email security workflows end to end. Unlike rigid playbook-based systems, Torq dynamically analyzes phishing emails, validates authentication headers, enriches sender data, and triggers response actions automatically. With 300+ integrations, Torq connects to your mailbox, SIEM, and other analysis tools to deliver continuous, adaptive protection against spoofed or malicious emails.