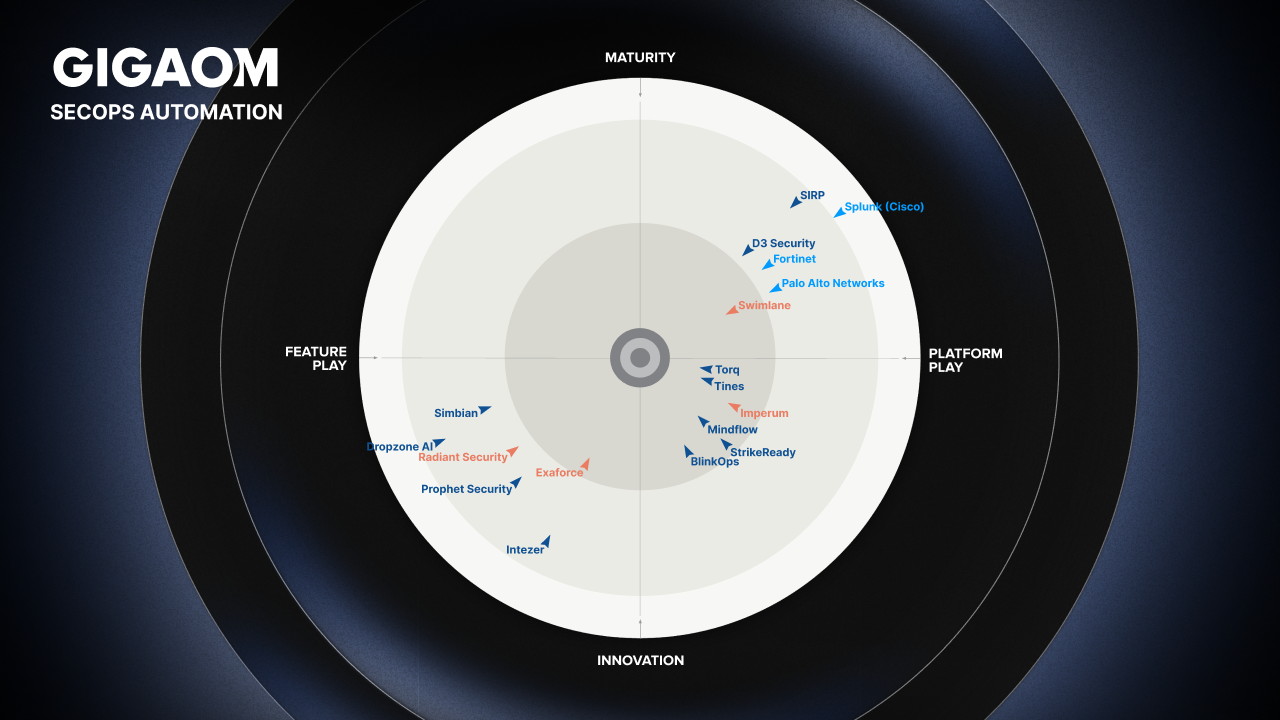
Contents
Get a Personalized Demo
See how Torq harnesses AI in your SOC to investigate, prioritize, and respond to threats faster.
TL;DR
- A formal incident response plan defines roles, responsibilities, escalation paths, and communication protocols before an incident ever occurs.
- Playbooks create consistent, repeatable responses for specific incident types.
- Speed is the defining variable in containment: organizations take an average of 204 days to identify a breach and 73 days to contain it, according to the IBM Report. Automation closes that gap.
- AI-driven triage and predefined automated containment actions — such as endpoint quarantine and access revocation — dramatically reduce MTTD and MTTR.
- The Torq 2026 AI SOC Leadership Report shares that 90% of security leaders say AI has positively impacted SOC workload.
No one wants to be mid-breach, staring at a flood of alerts, wondering who’s supposed to be doing what. Yet that’s exactly where many security teams find themselves when an incident hits.
The financial stakes are significant. According to the IBM Cost of a Data Breach Report, the global average cost of a data breach fell to $4.44 million in 2025 — down 9% from $4.88 million the prior year, marking the first decline in five years, driven by faster detection and containment powered by AI-driven defenses. But that global improvement masks a more troubling reality closer to home: U.S. breach costs hit a record high of $10.22 million.
The difference between a contained incident and a catastrophic one often comes down to how prepared your team was before the alert fired. This guide walks through incident response best practices across the six phases of the incident response (IR) lifecycle — from preparation through lessons learned — with a focus on building processes that are repeatable, communication-driven, and increasingly automated.
It’s Time to Prepare for a Security Incident
The old saying holds: you don’t rise to the occasion; you fall to your level of preparation. In incident response, preparation is everything. You’re not ready for what you haven’t planned for.
Develop and Maintain a Formal IR Plan
Your incident response plan needs to live, breathe, and evolve alongside your threat landscape. It should define:
- Clear roles and responsibilities for every stakeholder (IT, Legal, Communications, Executive)
- Escalation paths and decision-making authority
- Communication protocols for both internal teams and external parties
- Criteria for what constitutes a “security incident” worth escalating
The plan only works if people actually know it exists and understand their role in it. Socialize it broadly and revisit it annually — or after any major incident or organizational change.
Build and Test Incident Response Playbooks
A plan tells you what to do. Playbooks tell you how to do it, step by step, for specific scenarios. Build out playbooks for your most common incident types: phishing, ransomware protection, credential compromise, insider threats, and supply chain attacks, to name a few.
Good playbooks remove ambiguity. When an analyst is under pressure at 2am, the last thing they should be doing is improvising. Playbooks create a consistent, repeatable response regardless of who’s on shift — and they’re the foundation of incident response automation when you’re ready to operationalize them at scale.
Conduct Regular Training and Tabletop Exercises
Writing the playbook is step one. Testing is where most teams fall short.
Run tabletop exercises at least twice a year and make them cross-functional. Pull in Legal, HR, Communications, and Executive leadership, not just IT and security.
These exercises surface gaps before a real attacker does, build muscle memory across the team, and often reveal uncomfortable truths about communication bottlenecks or unclear ownership. That’s exactly the point.
Identification and Containment of a Security Incident (Speed Is Key)
Once something is happening, every minute matters. According to the IBM Report, organizations took an average of 204 days to identify a breach and another 73 days to contain it — a combined lifecycle of nearly 9 months. Breaches contained within 200 days averaged $3.61 million in costs; those that stretched beyond that mark averaged $4.87 million.
Time is money, quite literally.
Centralize Alert Triage with Automation
Your analysts cannot manually sift through thousands of alerts per day and catch what matters. This is where SIEM and modern AI-driven platforms earn their keep.
Centralizing alert ingestion and automating correlation, prioritization, and routing dramatically reduces Mean Time to Detection (MTTD). The IBM report found that organizations that extensively use AI and automation across their SOC saw their time to identify and contain a breach cut by nearly 100 days on average compared to those that do not use these technologies. The goal is to get the right information in front of the right analyst as fast as possible, with the noise already filtered out.
Torq’s own 2026 AI SOC Leadership Report, based on a survey of more than 450 CISOs and security leaders, found that 72% of teams are now comfortable with fully autonomous AI handling medium-severity incidents and below — the alerts that make up the bulk of SOC volume. SOC teams that embrace AI-driven triage aren’t replacing analysts; they’re freeing them up for the work that actually requires human judgment.
Enforce Pre-Defined Containment Strategies
For high-severity threats, containment cannot wait for a human to read an email and decide what to do. Pre-define your containment actions and, where possible, automate them.
Common automated containment steps include network segmentation, endpoint quarantine, and access revocation. When these are tied to specific threat signatures or alert conditions, they can execute in seconds — stopping lateral movement before it becomes a full-blown breach. Automated SOC incident response workflows make this kind of speed achievable without burning out your analysts.
It’s worth noting that stolen and compromised credentials were the most common initial attack vector in 2024, accounting for 16% of all breaches — and they took the longest to identify and contain at an average of 292 days. Pre-defined containment steps for credential-based incidents (like automated access revocation) can meaningfully close that window.
Treat Communication as a Core Incident Response Best Practice
This one gets underestimated constantly. When an incident is active, poor communication is often as damaging as the attack itself — both internally and externally.
Before an incident happens, establish a dedicated, secure communication channel (a separate incident Slack channel, a secure bridge line, etc.) so critical information doesn’t get buried in normal traffic. Pre-draft templated messages for key stakeholders: what executives need to know, what Legal needs to escalate, what customers need to hear. When the time comes, you want to be filling in the blanks, not writing from scratch.
Eradication and Recovery from a Security Incident (Restoring Trust)
Containment stops the bleeding. Eradication and recovery close the wound and get you back on your feet — but rushing this phase is a mistake many organizations make. IBM’s data shows that only 12% of breached organizations fully recovered, and for most of those, recovery took more than 100 days.
Focus on Root Cause Eradication
Patching the symptom and calling it done is how you get hit by the same attack twice. Before restoring any affected system to production, make sure you’ve identified and eliminated the root cause — the actual access vector the attacker used to get in.
This means validating that malicious persistence mechanisms (backdoors, compromised credentials, malicious scheduled tasks) are fully removed and that any exploited vulnerabilities are patched. Check out common security incident categories to better understand the typical root causes tied to different attack types.
Secure System Recovery with Known Good Backups
Restoring from backups sounds straightforward, but the “known good” part is a lot of work. Backups need to be regularly validated and, ideally by an active attacker.
After restoring, validate system integrity before bringing anything back online. Monitor restored systems closely for signs of residual infection in the first 24–72 hours. Trust, but verify — then verify again.
Isolate and Preserve Forensic Evidence
This step often gets skipped in the rush to recover, and that’s a problem. Logs, memory dumps, disk images, and network captures collected during an incident are invaluable for the post-mortem, potential legal action, and regulatory compliance.
Collect and preserve forensic evidence in a secure, tamper-evident manner — separate from the systems being remediated. IBM’s research found that organizations that involved law enforcement in ransomware incidents saw breach costs reduced by roughly $1 million on average. Preserved forensic evidence is what makes that coordination possible. Once it’s gone or contaminated, you can’t get it back.
Lessons Learned from a Security Incident (Continuous Improvement)
The incident is over. The temptation is to close the ticket and move on. Resist that temptation.
Conduct a Blameless Post-Mortem
A blameless post-mortem is exactly what it sounds like: a structured review of what happened, why defenses failed, and how to prevent recurrence — without assigning personal fault to individuals.
This framing matters more than it might seem. When people fear blame, they get defensive, withhold information, and you learn less. When the focus shifts from people to systems and processes, you get honest answers and actionable insights. Document technical failures, procedural gaps, and communication breakdowns. All of it is fair game.
Aim to hold the post-mortem within a week of resolution, while details are still fresh.
Implement Actionable Improvements
A post-mortem that doesn’t result in change is just a meeting. Convert every finding into a concrete, assigned, time-bound action item — whether that’s patching a vulnerable system, revising a playbook, adding a detection rule, or making the case for a new tool.
Track completion of these items like you’d track any other project. Report on progress to leadership. This is how incident response matures from reactive to genuinely resilient.
The IBM data reinforces the ROI here: organizations with established IR teams and regular security testing saved an average of $248,000 per year compared to those without, and those savings compound with every iteration of improvement.
Torq’s Role in Operationalizing Incident Response Best Practices
Reading about IR best practices is easy. Executing them consistently, at speed, across a sprawling and constantly changing security tool stack — that’s the hard part.
Torq’s own research underscores just how hard. The 2026 AI SOC Leadership Report found that while 90% of security leaders say AI has positively impacted SOC workload, the average SOC is still running 7 separate AI-powered tools — with 80% relying on fragmented point solutions rather than a unified platform.
AI is working. The way it’s been deployed isn’t.
That’s the gap the Torq AI SOC Platform is built to close. Torq provides the orchestration layer that enforces incident response best practices at machine speed — automatically triaging alerts, executing containment actions, routing escalations, and keeping communication flowing, all without requiring an analyst to manually touch every step.
Torq’s AI Agents for the SOC can be deployed across the full IR lifecycle: from initial detection through containment and into case management. And with Case Management built in, every incident is automatically documented — giving your team the forensic trail they need for post-mortems and compliance, without adding manual work.
For teams that want to build and customize agentic response workflows without a deep engineering lift, Torq’s Agentic Builder makes that possible. And for a deeper look at what AI is actually doing inside modern SOCs, the 2026 AI SOC Leadership Report breaks it all down with data from more than 450 CISOs and security leaders.
The Gap Between Plan and Reality
Effective incident response is a measure of organizational maturity. Any security team can write a plan. The ones that consistently limit breach impact are the ones that have tested it, automated the repetitive parts, and committed to learning from every incident — not just the bad ones.
Here’s the question worth sitting with: How wide is the gap between your documented IR plan and your actual response time the last time something went wrong?
If the answer makes you uncomfortable, that’s useful information. Start with preparation, invest in automated incident response, and build the muscle for blameless continuous improvement. The next incident is coming. The only variable is how ready you’ll be.
Ready to see what 450+ security leaders revealed about the state of AI in the SOC?
FAQs
The six phases of incident response are: Preparation, Identification, Containment, Eradication, Recovery, and Lessons Learned. Preparation involves building IR plans and playbooks before an incident occurs. Identification focuses on detecting and confirming a security incident. Containment limits the spread of the threat. Eradication removes the root cause. Recovery restores systems to normal operations. Lessons Learned captures what happened and drives continuous improvement through post-mortems and process updates. For a deeper dive into each phase, see Torq’s incident response plan guide.
An incident response plan should define roles and responsibilities for all stakeholders — including IT, Legal, HR, Communications, and Executive leadership — along with clear escalation paths, decision-making authority, and communication protocols for both internal and external parties. It should also establish criteria for what qualifies as a reportable security incident, include step-by-step playbooks for common incident types, and outline procedures for preserving forensic evidence. The plan should be reviewed and updated at least annually and tested regularly through tabletop exercises. See common security incident categories to help inform which playbooks to prioritize.
A blameless post-mortem is a structured review conducted after a security incident is resolved. The goal is to understand what happened, why defenses failed, and how to prevent recurrence — without assigning personal fault to individuals. The focus stays on systems, processes, and procedural gaps rather than individual mistakes. Findings are documented and converted into prioritized, assigned action items. This approach encourages honest reporting, surfaces more useful insights, and drives continuous improvement in security posture. The Torq 2026 AI SOC Leadership Report explores how leading security teams are structuring continuous improvement across their SOC operations.
Automation reduces the time it takes to detect and contain security incidents by eliminating manual, repetitive steps from the response process. Rather than waiting for an analyst to read an alert and decide on next steps, automated workflows can instantly triage alerts, quarantine affected endpoints, revoke compromised credentials, and notify stakeholders — all within seconds of detection. The IBM Cost of a Data Breach Report found that organizations using AI and automation extensively across their SOC identified and contained breaches nearly 100 days faster than those that did not, and incurred an average of $2.22 million less in breach costs. Learn more about how automated SOC incident response works in practice.
The most critical incident response best practices in 2026 center on preparation, speed, and continuous improvement. That means maintaining a formal IR plan with defined roles and tested playbooks, centralizing alert triage with AI-driven automation to cut detection and containment times, enforcing pre-defined containment actions for high-severity threats, preserving forensic evidence for post-incident analysis, and conducting blameless post-mortems that produce concrete, tracked action items. Organizations that combine established IR teams, regular testing, and AI-driven automation see measurably lower breach costs and faster recovery times.